1. Introduction
Land use/land cover (LULC) information is urgently required for policy making for it provides vital inputs for various developmental, environmental and resource planning applications, as well as regional and global scale process modeling [
1,
2]. Remote sensing classification is an important way to extract LULC information, and the selection of classification methods is a key factor influencing its accuracy.
Traditional classification and intelligence methods have their own limitations. The most commonly used maximum likelihood classification shows difficulty in extracting different objects with same spectra and same objects with different spectra, which results in a low classification accuracy [
3]. Artificial Neural Network (ANN) [
4,
5,
6], Support Vector Machine (SVM) [
7,
8], and Fuzzy classification methods [
9,
10,
11], which are based on image spectral characteristics, cannot take multi-features (such as Digital Elevation Model (DEM), spectral information, Iterative Self-organizing Data Analysis Technique (ISODATA) result, Minimum Noise Fraction (MNF) result, and abundance) into account, and their complex algorithms may also lead to low classification efficiency. Object-oriented classification delineates objects from remote sensing images by obtaining a variety of additional spatial and textural information, which is important for improving the accuracy of remote sensing classification [
12,
13]; however, for low resolution imagery or fragmented landscapes and complex terrain, its classification accuracy is much lower [
14].
Decision tree (DT) has been widely used in remote sensing classification, for it can fuse complex features related to terrain, texture, spectral, and spatial distribution to improve classification accuracy, and its advantages include the ability to handle data measured at different scales and various resolutions, rapid DT algorithms, and no statistical assumptions [
15]. In recent years, many applications have applied DT algorithms to classify remote sensing data, such as mapping tropical vegetation cover [
16] or urban landscape dynamics [
17], and they obtained good results. Although DT is very effective for LULC classification, it is also pixel-based and cannot effectively eliminate the influence of mixed pixels during the classification process, especially for low resolution imagery, fragmented landscapes, and complex terrain. The presence of mixed pixels reduces classification accuracy to a great extent for low resolution imagery, and the cost of using high-resolution images is very great for large-scale LULC classification.
There are two mainstream methods for eliminating mixed pixels: linear and nonlinear spectral models. The gray value of a mixed pixel is a linear combination of different pure pixel’s gray value in a linear spectral model, which has the advantages of clear physical meaning and strict theoretical basis. This kind of model is widely used, and the linear least squares algorithm is usually applied to decomposite mixed pixels. The construction and calculation of a nonlinear spectral model is much more difficult than those of a linear model, and a nonlinear spectral mixture model uses the sum of quadratic polynomials and residuals to represent the gray value. However, such a model is nonlinear and cannot be calculated directly, and thus an iterative algorithm is needed to solve the problem of nonlinear decomposition [
18,
19].
At present, mixed pixel unmixing methods are mainly emphasized in the selection of endmember and abundance extraction, especially for endmember selection, Endmember selection is an important part of mixed pixel decomposition, and the primary approaches are as follows: (1) obtaining spectral signals by using a spectrometer to measure in field or selecting from an available spectral library, such as ENVI standard spectral library, known as “Reference Endmembers” [
20,
21,
22]; (2) directly selecting endmembers from the image to be classified, and then adjusting and modifying the endmembers until they are sufficient, known as “Image Endmembers”; and (3) using a combination of “Reference Endmembers” and “Image Endmembers”, in order to ensure that endmembers are primarily dependent on the adjustment of reference and the correction of image [
23,
24]. The key for mixed pixel decomposition is the selection of appropriate endmembers [
25]. Theoretically, the premise for solving mixed pixel linear equations is to keep the number of endmembers as less than or equal to
i + 1 (
i is the number of image bands). The following methods are generally used to extract endmembers from images: Geometric Vertex method, Pure Pixel Index (PPI) combination n-dimensional scatter plot visualization tool [
26], or Sequential Maximum Angle Convex Cone (SMACC) for automatic extraction. In addition, mixed pixel unmixing also emphasized the specific location of each mixed component, which can effectively improve image classification, object recognition, and extraction accuracy.
Little research has been done on integrating mixed pixel decomposition and decision trees to improve LULC classification. Therefore, this study aimed to design a methodological framework to carry out LULC classification by integrating pixel unmixing and decision tree, and a Landsat-8 OLI image of the Yunlong Reservoir Basin in Kunming, China, was used to test this proposed framework. The proposed method is provided in next section, followed by its main results and discussions in
Section 3 and
Section 4, and the conclusion is given at the end.
3. Results
3.1. Mixed Pixel Decomposition
The abundance maps of nine endmembers that were derived from mixed pixel decomposition, including arboreal forest, sparse shrub, high albedo, grassland, water, arable land (including crops), arable land (no crops), low albedo, and desertand bare surface, were shown in
Figure 5. Decomposition accuracy gradually increases with decreasing RMSE, and the overall RMSE error for endmember abundance was approximately 0.174913 (
Table 7), which satisfied the demands of this study.
3.2. LULC Classification
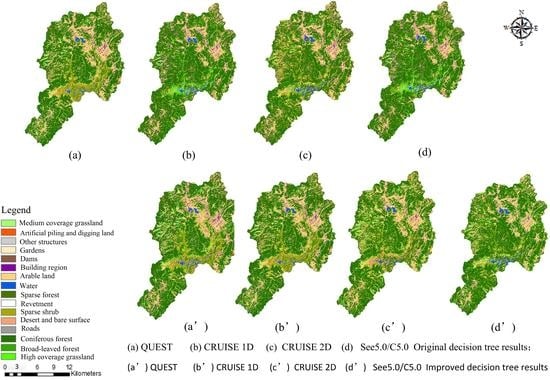
Some LULC types were divided into Level 2 to Level 3 classes (
Table 4), including: arable land, gardens, coniferous forest, broad-leaved forest, sparse forest, sparse shrub, medium coverage grassland, high coverage grassland, building region, roads, dams, other structures, artificial piling and digging land, revetment, desert and bare surface, and water, for a total of 16 LULC types (
Figure 6).
The basic precision index of overall accuracy, user’s accuracy and Kappa coefficient were calculated, as shown in
Table 8. The classification accuracy for the improved decision tree method was generally higher than that of the original decision tree (
Table 8). Accuracy was gradually reduced from QUEST, CRUISE 2D, CRUISE 1D to See5.0/C5.0. Kappa coefficients, overall accuracies of the original and improved decision tree method using QUEST were more than 85%, and the improved decision tree method even reached 95%. On the contrary, the accuracies of the original decision tree method using CRUISE 2D, CRUISE 1D and See5.0/C5.0 were no more than 85%, while the improved decision tree method were more than 85%, and those results were better than those of the original decision tree method using QUEST. The Kappa coefficient and overall accuracy of the QUEST improved decision tree were 0.1% and 10%, respectively, and they were better than those of the original method. Those values also increased by 0.1% and 10% for CRUISE 1D, by 0.06% and 8% for CRUISE 2D, by 0.11% and 12% for See5.0/C5.0. Overall, the Kappa coefficients and overall accuracy of the improved decision tree method were improved by averages of 0.093% and 10%, respectively.
McNemar’s test confirmed that the improved decision tree method was significantly better than original decision tree method using QUEST (Z = 5.35, p < 0.05), CRUISE 2D (Z = 5.01, p < 0.05), CRUISE 1D (Z = 4.30, p < 0.05) and See5.0/C5.0 (Z = 4.12, p < 0.05). These results indicate that each of the proposed improved decision tree methods plays important roles in LULC classification.
3.3. Classification Error Analysis
The areas of all the LULC types that were derived from the original and improved decision tree were calculated to analyze the classification accuracy and error (
Table 9). The areas for LULC types with clear spectral and texture features (arable land, coniferous forest, dams, desert and bare surface, and water) were consistent across different extraction algorithms, considering the original and improved decision tree method.
There were significant differences, however, in the areas for LULC types with spectral confusion and mixed pixels, such as sparse shrub, sparse forest, high coverage grassland, building region, other structures, and artificial piling and digging land. Clear under- or over-estimations occurred, in particular, in high coverage grassland, medium coverage grassland, and construction areas. For example, the area results from the original decision tree using QUEST, CRUISE 1D, CRUISE 2D and See5.0/C5.0 were 24.33, 10.43, 26.65 and 24.88 km2 for medium coverage grassland, and 32.44, 27.83, 27.25, and 36.77 km2 for high coverage grassland, respectively, while under the improved decision tree method, they were 34.33, 20.43, 36.65, and 34.88 km2 for low coverage grassland, and 17.44, 11.82, 10.25, and 24.77 km2 for high coverage grassland, respectively; and, on average, the area estimations for these classes were improved by nearly 10 km2. The area estimations for gardens and structures differed by an order of magnitude. While the area results from the original decision tree using QUEST and CRUISE 1D were 9.39 and 9.04 km2 for building region, but under the improved decision tree method, they were 24.38 and 12.04 km2, respectively; and on average, the area estimations for this class was improved by nearly 3 km2.
4. Discussion
We found that the improved decision tree classification method that was proposed in this study was very effective in improving LULC classification accuracy. This result may be explained by that the improved decision tree method not only combined multi-features, but also fused mixed pixel decomposition theory and introduced abundance into decision tree calculations, which has rarely been done in prior classifications. This method solved issues that the original decision tree classification for LULC types with serious spectral confusion and mixed pixels was poor, such as arboreal forest, sparse shrub, high albedo, grassland, water, arable land (including crops), arable land (no crops), low albedo, desert, and bare surface . These objects contained mixed pixels, resulting in lower classification accuracy, but for the classification of the LULC types with obvious characteristics, such as water and arable land, it was more accurate. The improved decision tree method was able to successfully classify mixed pixels, and it had high accuracy, especially in regions with fragmented landscape and complex terrain. When abundance maps were introduced into the decision tree dataset, the decision tree algorithms could better mine potential classification rules that increased the probability of identifying objects. Therefore, it was easy to identify LULC types like sparse shrub, sparse forest, grassland, construction area, other structures and artificial digging pile.
Due to the fragmented landscape and complex terrain in this study area, the traditional training sample selection method that was based on two-dimensional imagery was limited. Although it was attempted repeatedly, it was impossible to select 16 LULC types, while ensuring that their ROI separability was greater than 1.8. Unqualified training samples can reduce the classification accuracy to a large extent. To overcome this limitation, we proposed a new training sample selection method using a 3D terrain that was created by OLI image fusion DEM to select ROIs, which circumvented the traditional method that was based on a two-dimensional image. This method was not limited to the color synthesis principle, but also used different 3D angles (looking-down, looking-up, head, side-looking) to select ROIs. It allowed for us to efficiently select 16 LULC samples and to improve their ROI separability to greater than 1.9, and most of them reached 2.0. These highly qualified training samples helped improving the accuracy of subsequent classification.
Although the improved decision tree method for LULC classification that is proposed in this study was effective and obtained a high classification accuracy, only the main decision tree algorithms (QUEST, CRUISE 2D, CRUISE 1D, See5.0/C5.0) were tested, while other algorithms, such as Classification and Regression Tree (CART) and Iterative Dichotomiser 3 (ID3), were not tested. We just used linear spectral model to obtain abundance maps of nine endmembers, not using non-linear spectral model in this study. It is worthwhile to study whether non-linear spectral models can obtain better abundance of mixed pixel decomposition. We also did not compare this proposed method with other methods, such as maximum likelihood, ANN, and SVM. The future works should be carried out to simplify the decision tree dataset without affecting the classification accuracy, and to try to use additional decision tree algorithms to finalize the comparison. In addition, non-linear spectral models will be used to obtain abundance maps in this study, and the results should be compared with the linear spectral model. Besides, we will strengthen the contrast of different methods and establish an adaptive method to implement the comparative assessment of classification accuracy.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}