Panoptic Segmentation-Based Attention for Image Captioning



Abstract
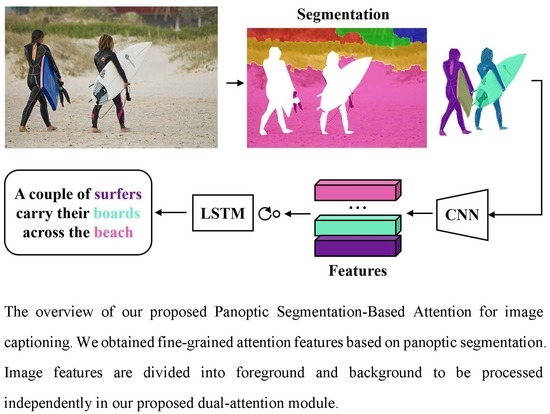
:
1. Introduction
- Introducing a novel panoptic segmentation-based attention mechanism together with a dual-attention module that can focus on more fine-grained regions at a mask-level when generating captions. To our best knowledge, we are the first to incorporate panoptic segmentation into image captioning.
- We explored and evaluated the impact of combining segmentation features and stuff regions on image captioning. Our study reveals the significance of the fine-grained attention region features and the scene information provided by stuff regions.
- Our proposed method is evaluated on the MSCOCO [11] dataset. Results show that our approach outperforms the baseline detection-based attention approach, improving the CIDEr score from 112.3 to 119.4. Our approach achieves competitive performance against state-of-the-art.
2. Related Work
3. Captioning Models
3.1. Encoder-Decoder Framework
3.2. Up-Down Attention Model
3.3. Dual-Attention Module for Panoptic Segmentation Features
4. Attention Regions
4.1. Detection Regions
4.2. Segmentation Regions
5. Feature Extraction
6. Experimental Results
6.1. Dataset
6.2. Implementation Details
6.3. Evaluation
6.3.1. Segmentation-Region Features versus Detection-Region Features
6.3.2. With Stuff versus without Stuff
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Jin, J.; Fu, K.; Cui, R.; Sha, F.; Zhang, C. Aligning where to see and what to tell: image caption with region-based attention and scene factorization. arXiv 2015, arXiv:1506.06272. [Google Scholar]
- Pedersoli, M.; Lucas, T.; Schmid, C.; Verbeek, J. Areas of attention for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1242–1250. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; Volume 3, p. 6. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. COCO-Stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1209–1218. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9404–9413. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Yang, Z.; Yuan, Y.; Wu, Y.; Cohen, W.W.; Salakhutdinov, R.R. Review networks for caption generation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2361–2369. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4651–4659. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 6, p. 2. [Google Scholar]
- Wang, W.; Chen, Z.; Hu, H. Hierarchical attention network for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8957–8964. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—NIPS’15, Montreal, QC, Canada, 7–12 December 2015; Volume 2, pp. 2017–2025. [Google Scholar]
- Yang, Z.; Zhang, Y.J.; ur Rehman, S.; Huang, Y. Image Captioning with Object Detection and Localization. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 109–118. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Neural Baby Talk. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7219–7228. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Fu, K.; Jin, J.; Cui, R.; Sha, F.; Zhang, C. Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2321–2334. [Google Scholar] [CrossRef] [PubMed]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Liu, A.; Qiu, Y.; Wong, Y.; Su, Y.; Kankanhalli, M. A Fine-Grained Spatial-Temporal Attention Model for Video Captioning. IEEE Access 2018, 6, 68463–68471. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Q.; Wang, Y.; Chen, F. Fine-Grained and Semantic-Guided Visual Attention for Image Captioning. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1709–1717. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Dai, B.; Ye, D.; Lin, D. Rethinking the form of latent states in image captioning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 282–298. [Google Scholar]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10685–10694. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 2018, 8–14 September; pp. 684–699.
- Liu, X.; Li, H.; Shao, J.; Chen, D.; Wang, X. Show, tell and discriminate: Image captioning by self-retrieval with partially labeled data. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 338–354. [Google Scholar]
- Dai, B.; Lin, D. Contrastive learning for image captioning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 898–907. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. arXiv 2016, arXiv:1611.07709. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. SGN: Sequential grouping networks for instance segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MA, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Association for Computational Linguistics Workshop, Barcelona, Spain, 21–26 July 2004; Available online: https://www.aclweb.org/anthology/W04-1013.pdf (accessed on 20 December 2019).
- Zhou, L.; Zhang, Y.; Jiang, Y.G.; Zhang, T.; Fan, W. Re-Caption: Saliency-Enhanced Image Captioning Through Two-Phase Learning. IEEE Trans. Image Process. 2019, 29, 694–709. [Google Scholar] [CrossRef] [PubMed]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5561–5570. [Google Scholar]
- Chen, X.; Ma, L.; Jiang, W.; Yao, J.; Liu, W. Regularizing RNNs for Caption Generation by Reconstructing the Past With the Present. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Jiang, W.; Ma, L.; Chen, X.; Zhang, H.; Liu, W. Learning to Guide Decoding for Image Captioning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Dognin, P.; Melnyk, I.; Mroueh, Y.; Ross, J.; Sercu, T. Adversarial Semantic Alignment for Improved Image Captions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10463–10471. [Google Scholar]
- Gu, J.; Cai, J.; Wang, G.; Chen, T. Stack-Captioning: Coarse-to-Fine Learning for Image Captioning. In Proceedings of theThirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lu, S.; Hu, R.; Liu, J.; Guo, L.; Zheng, F. Structure Preserving Convolutional Attention for Image Captioning. Appl. Sci. 2019, 9, 2888. [Google Scholar] [CrossRef] [Green Version]
- Xian, Y.; Tian, Y. Self-Guiding Multimodal LSTM-when we do not have a perfect training dataset for image captioning. IEEE Trans. Image Process. 2019, 28, 5241–5252. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Iranmanesh, S.M. Empirical Upper-bound in Object Detection and More. arXiv 2019, arXiv:1911.12451. [Google Scholar]
- Divvala, S.K.; Hoiem, D.; Hays, J.H.; Efros, A.A.; Hebert, M. An empirical study of context in object detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1271–1278. [Google Scholar]
- Heitz, G.; Koller, D. Learning spatial context: Using stuff to find things. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 30–43. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-L | METEOR | CIDEr |
|---|---|---|---|---|---|---|---|
| Hard-Attention [2] | 71.8 | 50.4 | 35.7 | 25.0 | - | 23.0 | - |
| VIS-SAS [48] | 72.5 | 52.6 | 38.1 | 28.1 | 55.4 | 23.7 | 82.1 |
| Jin et al. [3] | 69.7 | 51.9 | 38.1 | 28.2 | 50.9 | 23.5 | 83.8 |
| ATT-FCN [13] | 70.9 | 53.7 | 40.2 | 30.4 | - | 24.3 | - |
| Zhang et al. [26] | 71.2 | 51.4 | 36.8 | 26.5 | - | 24.7 | 88.2 |
| Areas of Attention [4] | - | - | - | 30.7 | - | 24.5 | 93.8 |
| SCA-CNN [14] | 71.9 | 54.8 | 41.0 | 31.1 | 53.1 | 25.0 | 95.2 |
| Aneja et al. [49] | 72.2 | 55.3 | 41.8 | 31.6 | 53.1 | 25.0 | 95.2 |
| Fu et al. [23] | 72.4 | 55.5 | 41.8 | 31.3 | 53.2 | 24.8 | 95.5 |
| Lu et al. [54] | - | - | - | 33.1 | 53.9 | 25.8 | 99.3 |
| Chen et al. [50] | 74.0 | 57.6 | 44.0 | 33.5 | 54.6 | 26.1 | 103.4 |
| Jiang et al. [51] | 74.3 | 57.9 | 44.2 | 33.6 | 54.8 | 26.1 | 103.9 |
| Adaptive [15] | 74.2 | 58.0 | 43.9 | 33.2 | - | 26.6 | 108.5 |
| Att2all [28] | - | - | - | 34.2 | 55.7 | 26.7 | 114.0 |
| Dognin et al. [52] | - | - | - | - | - | 26.9 | 116.1 |
| Stack-Cap (C2F) [53] | 78.6 | 62.5 | 47.9 | 36.1 | 56.9 | 27.4 | 120.4 |
| DetectionAtt | 77.1 | 60.4 | 45.4 | 33.7 | 55.6 | 26.3 | 112.3 |
| InstanceSegAtt | 77.9 | 61.4 | 46.7 | 34.9 | 56.3 | 27.0 | 117.3 |
| PanopticSegAtt (w/o Dual-Attend) | 78.2 | 61.8 | 46.9 | 34.9 | 56.4 | 26.9 | 118.2 |
| PanopticSegAtt | 78.1 | 61.7 | 47.1 | 35.3 | 56.6 | 27.3 | 119.4 |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-L | METEOR | CIDEr |
|---|---|---|---|---|---|---|---|
| sgLSTM [55] | 67.9 | 49.9 | 36.5 | 26.9 | 49.9 | 23.5 | 82.1 |
| Aneja [49] | 71.5 | 54.5 | 40.8 | 30.4 | 52.5 | 24.6 | 91.0 |
| Adaptive [15] | 74.8 | 58.4 | 44.4 | 33.6 | 55.2 | 26.4 | 104.2 |
| Att2all [28] | - | - | - | 35.2 | 56.3 | 27.0 | 114.7 |
| Stack-Cap (C2F) [53] | 77.8 | 61.6 | 46.8 | 34.9 | 56.2 | 27.0 | 114.8 |
| PanopticSegAtt | 79.0 | 63.0 | 48.3 | 36.5 | 57.3 | 27.7 | 117.8 |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE-L | METEOR | CIDEr |
|---|---|---|---|---|---|---|---|
| DetectionAtt | 76.9 | 61.0 | 45.5 | 35.7 | 57.0 | 26.6 | 112.2 |
| InstanceSegAtt | 78.4 | 62.6 | 48.3 | 37.0 | 57.5 | 27.2 | 117.8 |
| PanopticSegAtt | 79.2 | 63.8 | 49.5 | 38.1 | 58.2 | 27.6 | 120.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, W.; Xiong, Z.; Sun, X.; Rosin, P.L.; Jin, L.; Peng, X. Panoptic Segmentation-Based Attention for Image Captioning. Appl. Sci. 2020, 10, 391. https://doi.org/10.3390/app10010391
Cai W, Xiong Z, Sun X, Rosin PL, Jin L, Peng X. Panoptic Segmentation-Based Attention for Image Captioning. Applied Sciences. 2020; 10(1):391. https://doi.org/10.3390/app10010391
Chicago/Turabian StyleCai, Wenjie, Zheng Xiong, Xianfang Sun, Paul L. Rosin, Longcun Jin, and Xinyi Peng. 2020. "Panoptic Segmentation-Based Attention for Image Captioning" Applied Sciences 10, no. 1: 391. https://doi.org/10.3390/app10010391