
Abstract
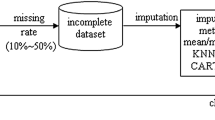
The purpose of this study is to investigate the generalization power of a modified backpropagation training algorithm referred to as "weight decay". In particular, we focus on the effect of the weight decay method on data sets with missing values. Three data sets with real missing values and three data sets with missing values created by randomly deleting attribute values are adopted as the test bank in this study. We first reconstruct missing values using four different methods, viz., standard backpropagation, iterative multiple regression, replacing by average, and replacing by zero. Then the standard backpropagation and the weight decay backpropagation are used to train networks for classification predictions. Experimental results show that the weight decay backpropagation can at least achieve a performance equivalent to the standard backpropagation. In addition, there is evidence that the standard backpropagation is a viable tool to reconstruct missing values. Experimental results also show that in the same data set, the higher the percentage of missing values, the higher the differential effects from reconstruction methods.
Similar content being viewed by others


References
M.L. Beale and R.J.A. Little, Missing values in multivariate analysis, Journal of the Royal Statistical Society B 37(1975)129 - 45.
A. Blumer, A. Ehrenfeucht, M.K. Warmuth and D. Haussler, Occam's razor, Information Processing Letters 24(1987)377 - 380.
S.F. Buck, A method of estimation of missing values in multivariate data suitable for use with an electronic computer, Journal of the Royal Statistical Society B 22(1960)302 - 306.
K. Chakraborty, K. Mehrotra, C.K. Mohan and S. Ranka, Forecasting the behavior of multivariate time series using neural networks, Neural Networks 5(1992)961 - 970.
Y. Chauvin, A back-propagation algorithm with optimal use of hidden units, in: Advances in Neural Information Processing Systems I D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1988, pp. 519 - 526.
F.L. Chung and T. Lee, A node pruning algorithm for backpropagation networks, International Journal of Neural Systems 3(1992)301 - 314.
E. Collins, S. Ghosh and C. Scofield, An application of a multiple neural-network learning system to emulation of mortgage underwriting judgments, in: Proceedings of the IEEE International Conference on Neural Networks Vol. 2, 1988, pp. 459- 466.
G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals, and Systems 2(1989)303 - 314.
S. Dutta and S. Shekhar, Bond-rating: A non-conservative application of neural networks, in: Proceedings of the IEEE International Conference on Neural Networks Vol. 2, 1988, pp. 443- 450.
S.E. Fahlman and C. Lebiere, The cascade-correlation learning architecture, in: Advances in Neural Information Processing Systems II D.S. Touretzky, ed., Morgan Kaufmann, San Mate, 1990, pp. 524 - 532.
A. Gupta and M. Lam, A neural net approach for estimating missing values in multivariate analysis, in: Proceedings of the 1993 National Meeting of the Decision Sciences Institute Vol. 2, Washington, DC, 1993, pp. 708 - 710.
S.J. Hanson and L. Pratt, A comparison of different biases for minimal network construction with back-propagation, in: Advances in Neural Information Processing Systems I D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1988, pp. 177 - 185.
J. Hertz, A. Krogh and R. Palmer, Introduction to the Theory of Neural Computation Addison-Wesley, Redwood City, 1991.
G.E. Hinton, Learning distributed representations of concepts, in: Proceedings of the 8th Annual Conference of the Cognitive Science Society Amherst, 1986, pp. 1 - 12.
K. Hornik, M. Stinchcombe and H. White, Multilayer feedforward networks are universal approximators, Neural Networks 2(1989)359 - 366.
J.R. Jang, Self-learning fuzzy controllers based on temporal backpropagation, IEEE Transactions on Neural Networks 3(1992)714-723.
A.H. Kramer and A. Sangiovanni-Vincentelli, Efficient parallel learning algorithms for neural networks, in: Advances in Neural Information Processing Systems I D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1988, pp. 40- 48.
W.J. Krzanowski, Principles of Multivariate Analysis Oxford Science Publications, New York, 1990.
Y. Le Cun, B. Boser, J.S. Denker, D. Henderson, R.E. Hubbard and L.D. Jackel, Handwritten digit recognition with a backpropagation network, in: Advances in Neural Information Processing Systems II D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1990, pp. 396- 404.
G.L. Martin and J.A. Pittmann, Recognizing hand-printed letters and digits, in: Advances in Neural Information Processing Systems II D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1990, pp. 405- 414.
T.M. Mitchell, The need for biases in learning generalization, in: Readings in Machine Learning J.W. Shavlik and T.G. Dietterich, eds., Morgan Kaufmann, San Mateo, 1990, pp. 184 - 191.
M.C. Mozer and P. Smolensky, Skeletonization: A technique for trimming the fat from a network via relevance assessment, in: Advances in Neural Information Processing Systems I D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1990, pp. 107 - 115.
P.M. Murphy and D.W. Aha, UCI Repository of Machine Learning Databases University of California-Irvine, Department of Information and Computer Science, 1992.
J.A. Ou, The information content of nonearnings accounting numbers as earnings predictors, Journal of Accounting Research 28(1990)144 - 163.
E.P. Patuwo, M.Y. Hu and M.S. Hung, Two-group classification using neural networks, Decision Sciences 24(1993)825 - 845.
J.R. Quinlan and R.L. Rivest, Inferring decision trees using the minimum description length principle, Information and Computation 80(1989)227 - 248.
D.E. Rumelhart, G. Hinton and R. Williams, Learning internal representation by error propagation, in: Parallel Distributed Processing D.E. Rumelhart and J. McClelland, eds., MIT Press, Cambridge MA, 1986, pp. 318 - 362.
L.M. Salchenberger, E.M. Cinar and N.A. Lash, Neural networks: A new tool for predicting thrift failures, Decision Sciences 23(1992)899 - 916.
R. Scalettar and A. Zee, Emergence of grandmother memory in feedforward networks: Learning with noise and forgetfulness, in: Connectionist Models and Their Implications: Readings from Cognitive Science D. Waltz and J.A. Feldman, eds., Ablex, Norwood, 1988, pp. 309 - 332.
T.J. Sejnowski, B.P. Yuhas, M.H. Goldstein, Jr. and R.E. Jenkino, Combining visual and acoustic speech signals with a neural network improves intelligibility, in: Advances in Neural Information Processing Systems II D.S. Touretzky, ed., Morgan Kaufmann, San Mateo, 1990, pp. 232-239.
J. Sietsma and R.J.F. Dow, Neural net pruning - why and how, in: IEEE International Conference on Neural Networks I IEEE, New York, 1988, pp. 325 - 333.
K.Y. Tam and M.L. Kiang, Managerial applications of neural networks: The case of bank failure predictions, Management Science 38(1992)926 - 947.
A.S. Weigend, D.E. Rumelhart and B.A. Huberman, Generalization by weight elimination with application to forecasting, in: Advances in Neural Information Processing Systems III R.P. Lippmann, J.E. Moody and D.S. Touretzky, eds., Morgan Kaufmann, San Mateo, 1991, pp. 875- 882.
Y. Yoon, G. Swales, Jr. and T.M. Margavio, A comparison of discriminant analysis versus artificial neural networks, Journal of Operational Research Society 44(1993)51 - 60.
Rights and permissions
About this article
Cite this article
Gupta, A., Lam, M. The weight decay backpropagation for generalizations with missing values. Annals of Operations Research 78, 165–187 (1998). https://doi.org/10.1023/A:1018945915940
Issue Date:
DOI: https://doi.org/10.1023/A:1018945915940