
Abstract
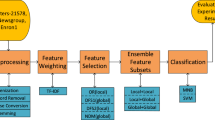
Ensemble learning constructs strong classifiers by training multiple weak classifiers, and is widely used in text classification field. In order to improve the text classification accuracy, a text length considered adaptive bootstrap aggregating (Bagging) ensemble learning algorithm (called TC_Bagging) for text classification is proposed. Firstly, the performances of different typical deep learning methods in processing long and short texts are compared, and the optimal base classifier groups are constructed for long and short texts. Secondly, an adaptive threshold group based random sampling method is proposed to realize the training of long text and short text sample subsets while retaining the proportions of samples in different categories. Finally, in order to avoid the problem that the sampling process may decrease the accuracy, the smooth inverse frequency (SIF) based text vector generation algorithm is combined with the traditional weighted voting classifier ensemble method to obtain the final classification result. By comparing TC_Bagging with several other baseline methods on three datasets, our evaluation suggests that the results of TC_Bagging are approximately 0.120, 0.300 and 0.060 better than that of RF, WAVE, RF_WMVE and RF_WAVE in terms of average F1, average sensitivity and average specificity measurements, respectively, showing that TC_Bagging has obvious advantage over typical ensemble learning algorithms.
















Similar content being viewed by others


References
Ali A, Zhu Y, Chen Q, et al (2019) Leveraging spatio-temporal patterns for predicting citywide traffic crowd flows using deep hybrid neural networks. In 2019 IEEE 25th international conference on parallel and distributed systems (ICPADS). IEEE. 125-132
Ali A, Zhu Y, Zakarya M (2021) A data aggregation based approach to exploit dynamic spatio-temporal correlations for citywide crowd flows prediction in fog computing. Multimed Tools Appl 80(20):31401–31433
Ali A, Zhu Y, Zakarya M (2022) Exploiting dynamic spatio-temporal graph convolutional neural networks for citywide traffic flows prediction. Neural Netw 145:233–247
Arora S, Li YZ, Liang YY, Ma T, Risteski A (2016) A latent variable model approach to PMI-based word embeddings. Transac Assoc Comput Linguis 4:385–399
Arora S, Liang YY, Ma TY (2017) A simple but tough-to-beat baseline for sentence embedding. In Proceedings of ICLR
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140
Bunkhumpornpat C, Sinapiromsaran K, Lursinsap C (2009) Safe-level-smote: safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In: Pacific-Asia conference on knowledge discovery and data mining. Springer, Berlin, Heidelberg, pp 475–482
Charbuty B, Abdulazeez A (2021) Classification based on decision tree algorithm for machine learning. J Appl Sci Technol Trends 2(01):20–28
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) Smote: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357
Cui YM, Che WX, Liu T, et al (2019) Pre-training with whole word masking for Chinese BERT arXiv preprint arXiv: 1906.08101.
De M, Romero FAB, Vasconcelos GC (2019) Boosting the performance of over-sampling algorithms through under-sampling the minority class. Neurocomputing 343:3–18
De'ath G, Fabricius KE (2000) Classification and regression trees: a powerful yet simple technique for ecological data analysis. Ecology 81(11):3178–3192
Deng J, Cheng L, Wang Z (2021) Attention-based BiLSTM fused CNN with gating mechanism model for Chinese long text classification. Comput Speech Lang 68:101182
Devlin J, Chang MW, Lee K, et al (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In proceedings of NAACL-HLT. pages 4171-4186
Diao S, Xu R, Su H, et al (2021) Taming pre-trained language models with N-gram representations for low-resource domain adaptation. In proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), 3336-3349.
Ding H, Wei B, Gu Z, Yu Z, Zheng H, Zheng B, Li J (2020) KA-ensemble: towards imbalanced image classification ensembling under-sampling and over-sampling. Multimed Tools Appl 79(21):14871–14888
Dogan A, Birant D (2019) A weighted majority voting ensemble approach for classification. In 4th International Conference on Computer Science and Engineering (UBMK). IEEE, 1-6
Du C, Huang L (2018) Text classification research with attention-based recurrent neural networks. Int J Comput Commun Contr 13(1):50–61
Fanny F, Muliono Y, Tanzil F (2018) A comparison of text classification methods k-NN, Naïve Bayes, and support vector machine for news classification. Jurnal Informatika: Jurnal Pengembangan IT 3(2):157–160
Galar M, Fernandez A, Barrenechea E (2012) A review on ensembles for the class imbalance problem: bagging, boosting, and hybrid-based approaches. IEEE Transac Syst Man Cybern Part C Appl Revi 42(4):463–484
Garcia S, Herrera F (2009) Evolutionary undersampling for classification with imbalanced datasets: proposals and taxonomy. Evol Comput 17(3):275–306
Giveki D (2021) Scale-space multi-view bag of words for scene categorization. Multimed Tools Appl 80(1):1223–1245
Guo B, Zhang C, Liu J, Ma X (2019) Improving text classification with weighted word embeddings via a multi-channel TextCNN model. Neurocomputing 363:366–374
Han H, Wang WY, Mao BH (2005) Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: International conference on intelligent computing. Springer, Berlin, Heidelberg, pp 878–887
He H, Bai Y, Garcia EA, et al (2008) Adasyn: adaptive synthetic sampling approach for imbalanced learning, In: Proceedings of the (IEEE world congress on computational intelligence). IEEE International Joint Conference on Neural Networks, IJCNN, IEEE. pp 1322–1328
Hsu KW, Srivastava J (2012) Improving bagging performance through multi-algorithm ensembles. Front Comput Sci 6(5):498–512
Huang L, Ma D, Li S, et al (2019) Text level graph neural network for text classification. arXiv preprint arXiv:1910.02356
Johnson R, Zhang T (2017) Deep pyramid convolutional neural networks for text categorization. In proceedings of ACL. pages 562-570
Joulin A, Grave E, Bojanowski P, (2016) Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759
Khoshgoftaar TM, Van HJ, Napolitano A (2011) Comparing boosting and bagging techniques with noisy and imbalanced data. IEEE Trans Pattern Anal Mach Intell 41(3):552–568
Kim Y (2014) Convolutional neural networks for sentence classification. In proceedings of EMNLP, pages 1746-1751
Kim H, Kim H, Moon H, Ahn H (2011) A weight-adjusted voting algorithm for ensembles of classifiers. J Korean Statis Soc 40(4):437–449
Kim A, Myung J, Kim H (2020) Random forest ensemble using a weight-adjusted voting algorithm. J Korean Data Inform Sci Soc 31(2):427–438
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980
Lacy SE, Lones MA, Smith SL (2015) A comparison of evolved linear and non-linear ensemble vote aggregators. In: IEEE congress on evolutionary computation (CEC). IEEE. 758-763
Lan Z, Chen M, Goodman S, et al (2020) ALBERT: A lite BERT for self-supervised learning of language representations. In proceedings of ICLR
Li S, Zhao Z, Hu RF, et al (2018) Analogical reasoning on Chinese morphological and semantic relations. In Proceedings of ACL
Li C, Peng X, Peng H, et al (2021) TextGTL: Graph-based Transductive Learning for Semi-Supervised Text Classification via Structure-Sensitive Interpolation. In proceedings of IJCAI
Li Q, Peng H, Li J, Xia C, Yang R, Sun L, Yu PS, He L (2022) A survey on text classification: from traditional to deep learning. ACM Transac Intel Syst Technol (TIST) 13(2):1–41
Liu G, Guo J (2019) Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 337(APR.14):325–338
Liu XY, Wu JX, Zhou ZH (2009) Exploratory undersampling for classimbalance learning. IEEE Transac Syst, Man, Cyberne, Part B: Cybernetics 39(2):539–550
Luengo J, Fernández A, Garica S, Herrera F (2011) Addressing data complexity for imbalanced data sets: analysis of SMOTE-based oversampling and evolutionary undersampling. Soft Comput 15(10):1909–1936
Luo W, Zhang L (2022) Question text classification method of tourism based on deep learning model. Wirel Commun Mob Comput 2022:4330701–4330709
Marcińczuk M, Gniewkowski M, Walkowiak T, et al (2021) Text document clustering: Wordnet vs. TF-IDF vs. word embeddings. In proceedings of the 11th global Wordnet conference, 207-214
Matloob F, Ghazal TM, Taleb N, Aftab S, Ahmad M, Khan MA, Abbas S, Soomro TR (2021) Software defect prediction using ensemble learning: a systematic literature review. IEEE Access 9:98754–98771
Murphree DH, Arabmakki E, Ngufor C, Storlie CB, McCoy RG (2018) Stacked classifiers for individualized prediction of glycemic control following initiation of metformin therapy in type 2 diabetes. Comput Biol Med 103:109–115
Pappagari R, Zelasko P, Villalba J, et al (2019) Hierarchical transformers for long document classification. In IEEE automatic speech recognition and understanding workshop (ASRU). IEEE, 838-844
Peng H, Li J, He Y, et al (2018) Large-scale hierarchical text classification with recursively regularized deep graph-cnn. In proceedings of the 2018 world wide web conference (WWW). 1063-1072
Shah K, Patel H, Sanghvi D, Shah M (2020) A comparative analysis of logistic regression, random forest and KNN models for the text classification. Aug Human Res 5(1):1–16
Sun B, Chen HY, Wang JD et al (2018) Evolutionary under-sampling based bagging ensemble method for imbalanced data classification. Front Comput Sci China 012(002):331–350
Tang DY, Qin B, Feng XC, et al (2016) Effective LSTMs for target-dependent sentiment classification. Proceedings of COLING
Vaswani A, Shazeer N, Parmar N (2017) Attention is all you need. In proceedings of NIPS
Xie J, Hou Y, Wang Y, Wang Q, Li B, Lv S, Vorotnitsky YI (2020) Chinese text classification based on attention mechanism and feature-enhanced fusion neural network. Computing 102(6):683–700
Xu J, Cai Y, Wu X, Lei X, Huang Q, Leung HF, Li Q (2020) Incorporating context-relevant concepts into convolutional neural networks for short text classification. Neurocomputing 386:42–53
Yan P, Li H, Wang Z (2021) WNTC: an efficient weight news text classification model. 2021 Asia-Pacific conference on communications technology and computer science (ACCTCS). pp. 271-276
Yang ZC, Yang DY, Dyer C, et al (2016) Hierarchical attention networks for document classification. In proceedings of NAACL, pages 1480-1489
Yang M, Tu W, Wang J, et al (2017) Attention-based LSTM for target-dependent sentiment classification, in: Proceedings of the 31st AAAI conference on artificial intelligence, AAAI press, San Francisco, CA, United states, p. 5013–5014
Yao L, Mao C S, Luo Y (2017) Graph convolutional networks for text classification. In proceedings of AAAI
Ye Z, Geng Y, Chen J, et al (2020) Zero-shot text classification via reinforced self-training. In proceedings of the 58th annual meeting of the Association for Computational Linguistics. 3014-3024
Zhang H, Zhang J (2020) Text graph transformer for document classification. In proceedings of EMNLP
Zhang YF, Yu XL, Cui ZY, et al (2020) Every document owns its structure: inductive text classification via graph neural networks. In proceedings of ACL
Zhou ZH (2021) Ensemble learning, machine learning. Springer, Singapore, pp 181–210
Zhou Y, Mazzuchi TA, Sarkani S (2020) M-AdaBoost-A based ensemble system for network intrusion detection [J]. Expert Syst Appl 162(6):113864
Zulqarnain M, Ghazali R, Hassim YMM, Aamir M (2021) An enhanced gated recurrent unit with auto-encoder for solving text classification problems. Arab J Sci Eng 46(9):8953–8967
Acknowledgments
This research is supported by the National Natural Science Foundation of China (No. 61906220), the Ministry of education of Humanities and Social Science project (No. 19YJCZH178), National Social Science Foundation of China (No.18CTJ008), the Natural Science Foundation of Tianjin Province (No. 18JCQNJC69600), the National Key R&D Program of China (2017YFB1400700) and the Emerging Interdisciplinary Project of CUFE.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflicts of interest to this work. We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, Y., Liu, J. & Feng, L. Text length considered adaptive bagging ensemble learning algorithm for text classification. Multimed Tools Appl 82, 27681–27706 (2023). https://doi.org/10.1007/s11042-023-14578-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14578-9