
Abstract
In practical applications related to, for instance, machine learning, data mining and pattern recognition, one is commonly dealing with noisy data lying near some low-dimensional manifold. A well-established tool for extracting the intrinsically low-dimensional structure from such data is principal component analysis (PCA). Due to the inherent limitations of this linear method, its extensions to extraction of nonlinear structures have attracted increasing research interest in recent years. Assuming a generative model for noisy data, we develop a probabilistic approach for separating the data-generating nonlinear functions from noise. We demonstrate that ridges of the marginal density induced by the model are viable estimators for the generating functions. For projecting a given point onto a ridge of its estimated marginal density, we develop a generalized trust region Newton method and prove its convergence to a ridge point. Accuracy of the model and computational efficiency of the projection method are assessed via numerical experiments where we utilize Gaussian kernels for nonparametric estimation of the underlying densities of the test datasets.









Similar content being viewed by others
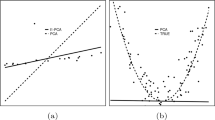

References
Baş, E.: Extracting structural information on manifolds from high dimensional data and connectivity analysis of curvilinear structures in 3D biomedical images. PhD thesis, Northeastern University, Boston, MA (2011)
Baş, E., Erdogmus, D.: Connectivity of projected high dimensional data charts on one-dimensional curves. Signal Process. 91(10), 2404–2409 (2011)
Baş, E., Erdogmus, D.: Sampling on locally defined principal manifolds. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2276–2279 (2011)
Belkin, M., Niyogi, P.: Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 15(6), 1373–1396 (2003)
Bishop, C.M.: Latent variable models. In: Jordan, M.I. (ed.) Learning in Graphical Models, pp. 371–403. MIT Press, Cambridge (1999)
Bishop, C.M., Svensén, M., Williams, C.K.I.: GTM: the generative topographic mapping. Neural Comput. 10(1), 215–234 (1998)
Carreira-Perpiñán, M.Á.: Gaussian mean-shift is an EM algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 29(5), 767–776 (2007)
Chacón, J.E., Duong, T., Wand, M.P.: Asymptotics for general multivariate kernel density derivative estimators. Stat. Sin. 21, 807–840 (2011)
Chen, D., Zhang, J., Tang, S., Wang, J.: Freeway traffic stream modeling based on principal curves and its analysis. IEEE Trans. Intell. Transp. Syst. 5(4) (2004)
Cheng, Y.: Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 17(8), 790–799 (1995)
Comaniciu, D., Meer, P.: Mean shift: a robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 24(5), 603–619 (2002)
Genovese, C.R., Perone-Pacifico, M., Verdinelli, I., Wasserman, L.: On the path density of a gradient field. Ann. Stat. 37(6A), 3236–3271 (2009)
Gorban, A.N., Kégl, B., Wunsch, D.C., Zinovyev, A.Y.: Principal Manifolds for Data Visualization and Dimension Reduction. Lecture Notes in Computational Science and Engineering, vol. 58. Springer, Berlin (2008)
Gould, N.I.M., Leyffer, S.: An introduction to algorithms for nonlinear optimization. In: Blowey, J.F., Craig, A.W., Shardlow, T. (eds.) Frontiers in Numerical Analysis, pp. 109–197. Springer, Berlin (2003)
Greengard, L., Strain, J.: The fast Gauss transform. SIAM J. Sci. Stat. Comput. 12(1), 79–94 (1991)
Hall, P., Sheather, S.J., Jones, M.C., Marron, J.S.: On optimal data-based bandwidth selection in kernel density estimation. Biometrika 78(2), 263–269 (1991)
Harkat, M.-F., Djelel, S., Doghmane, N., Benouaret, M.: Sensor fault detection, isolation and reconstruction using nonlinear principal component analysis. Int. J. Autom. Comput. 4, 149–155 (2007)
Hastie, T.: Principal curves and surfaces. PhD thesis, Stanford University (1984)
Hastie, T., Stuetzle, W.: Principal curves. J. Am. Stat. Assoc. 84(406), 502–516 (1989)
Jolliffe, I.T.: Principal Component Analysis. Springer, Berlin (1986)
Jones, M.C., Marron, J.S., Sheather, S.J.: A brief survey of bandwidth selection for density estimation. J. Am. Stat. Assoc. 91(433), 401–407 (1996)
Kégl, B.: Principal curves: learning, design, and applications. PhD thesis, Concordia University, Montreal, Canada (1999)
Kégl, B., Krzyzak, A.: Piecewise linear skeletonization using principal curves. IEEE Trans. Pattern Anal. Mach. Intell. 24(1), 59–74 (2002)
Kégl, B., Krzyzak, A., Linder, T., Zeger, K.: Learning and design of principal curves. IEEE Trans. Pattern Anal. Mach. Intell. 22(3), 281–297 (2000)
Moghaddam, B.: Principal manifolds and probabilistic subspaces for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 24(6), 780–788 (2002)
Moré, J.J., Sorensen, D.C.: Computing a trust region step. SIAM J. Sci. Stat. Comput. 4(3), 553–572 (1983)
Nocedal, J., Wright, S.J.: Numerical Optimization, 2nd edn. Springer, New York (2006)
Ortega, J.M.: Numerical Analysis: A Second Course. SIAM, Philadelphia (1990)
Ozertem, U., Erdogmus, D.: Locally defined principal curves and surfaces. J. Mach. Learn. Res. 12, 1249–1286 (2011)
Park, B.U., Marron, J.S.: Comparison of data-driven bandwidth selectors. J. Am. Stat. Assoc. 85(409), 66–72 (1990)
Roweis, S.T., Saul, L.K.: Nonlinear dimensionality reduction by locally linear embedding. Science 290(5500), 2323–2326 (2000)
Saul, L.K., Roweis, S.T.: Think globally, fit locally: unsupervised learning of low dimensional manifolds. J. Mach. Learn. Res. 4, 119–155 (2003)
Scott, D.W.: Multivariate Density Estimation: Theory Practice and Visualization. Wiley, New York (1992)
Sheather, S.J., Jones, M.C.: A reliable data-based bandwidth selection method for kernel density estimation. J. R. Stat. Soc., Ser. B, Methodol. 53(3), 683–690 (1991)
Stanford, D.C., Raftery, A.E.: Finding curvilinear features in spatial point patterns: principal curve clustering with noise. IEEE Trans. Pattern Anal. Mach. Intell. 22(6), 601–609 (2000)
Tenenbaum, J.B., de Silva, V., Langford, J.C.: A global geometric framework for nonlinear dimensionality reduction. Science 290(5500), 2319–2323 (2000)
Tibshirani, R.: Principal curves revisited. Stat. Comput. 2(4), 183–190 (1992)
Tipping, M.E., Bishop, C.M.: Probabilistic principal component analysis. J. R. Stat. Soc., Ser. B, Stat. Methodol. 61(3), 611–622 (1999)
Tsai, F.S.: Comparative study of dimensionality reduction techniques for data visualization. J. Artif. Intell. 3(3), 119–134 (2010)
Wand, M.P., Jones, M.C.: Kernel Smoothing. Chapman and Hall, London (1995)
Weinberger, K., Saul, L.: Unsupervised learning of image manifolds by semidefinite programming. Int. J. Comput. Vis. 70(1), 77–90 (2006)
Wilson, D.J.H., Irwin, G.W., Lightbody, G.: RBF principal manifolds for process monitoring. IEEE Trans. Neural Netw. 10(6), 1424–1434 (1999)
Acknowledgements
The first author was financially supported by the TUCS Graduate Programme. We would also like to thank Dr. Balázs Kégl for providing his datasets for our numerical tests and the referees for their constructive comments.
Author information
Authors and Affiliations
Corresponding author
Appendix: Proofs of Theorem 2.1 and Lemmata 3.1 and 3.6
Appendix: Proofs of Theorem 2.1 and Lemmata 3.1 and 3.6
Theorem 2.1
Let m>0, \(\mathcal{D}=\{\boldsymbol{\theta}\in\mathbb{R}^{d}\mid a_{i}\leq \theta_{i}\leq b_{i},i=1,2,\dots,m\}\) with a i <b i , i=1,2,…,m and let \(\boldsymbol{f}:\mathcal{D}\to\mathbb{R}^{d}\) be defined as
with some \(\boldsymbol{x}_{0}\in\mathbb{R}^{d}\) and mutually orthogonal vectors \(\{\boldsymbol{v}_{i}\}_{i=1}^{m}\subset\mathbb{R}^{d}\setminus\{\boldsymbol{0}\}\). If p is defined by Eq. (5) with n=1 and f 1=f, then \(\{\boldsymbol{f}(\boldsymbol{\theta}) \mid\boldsymbol{\theta}\in\mathcal{D}\}\subseteq R_{p}^{m}\).
Proof
Without loss of generality we can assume that x 0=0 and
where \(\boldsymbol{e}_{i}\in\mathbb{R}^{d}\) denotes a unit vector along the i-th coordinate axis. With some noise standard deviation σ>0, the gradient and Hessian of the marginal density (5) induced by the model of Sect. 2.1 with this function are
and
where
respectively, and I denotes the d×d identity matrix.
By Proposition 2.2, it suffices to consider the logarithm of the density p. For the Hessian of the logarithm of p, we obtain the expression
Since \(\sum_{j=1}^{m}\theta_{j}\boldsymbol{e}_{j}^{T}\boldsymbol{e}_{i}=0\) for all i=m+1,m+2,…,d, from Eqs. (39) and (40) we obtain
and
for all i=m+1,m+2,…,d. Substituting these expressions into Eq. (41) yields
for all i=m+1,m+2,…,d, which shows that the vectors e m+1,e m+2,…,e d span the d−m-dimensional eigenspace of the matrix ∇2logp(x) corresponding to the eigenvalue \(-\frac{1}{\sigma^{2}}\) for all \(\boldsymbol{x}\in\mathbb{R}^{d}\). Consequently, condition (6b) for logp(x) holds for all \(\boldsymbol{x}\in\mathbb{R}^{d}\). Furthermore, by Eq. (42) and the fact that p(x)>0 for all \(\boldsymbol{x}\in\mathbb{R}^{d}\), condition (6a) for logp(x) holds if and only if x∈ span(e 1,e 2,…,e m ).
On the other hand, from Eqs. (39)–(41) we obtain
for all i=1,2,…,m, where
Since it can be shown that F σ,i (x)>0 for all \(\boldsymbol{x}\in\mathbb{R}^{d}\) and i=1,2,…,m, we observe that
for all i=1,2,…,m and j=m+1,m+2,…,d. This shows that the eigenvalues of ∇2logp(x) corresponding to the eigenvectors in the subspace spanned by the vectors e 1,e 2,…,e m are strictly greater than the remaining ones for all \(\boldsymbol{x}\in\mathbb{R}^{d}\). Thus, the eigenvalues of ∇2logp(x) satisfy condition (6c) for all \(\boldsymbol{x}\in\mathbb{R}^{d}\). Since we showed above that for logp(x), condition (6b) holds for all \(\boldsymbol{x}\in\mathbb{R}^{d}\) and condition (6a) holds if and only if \(\boldsymbol{x}\in\operatorname{span}(\boldsymbol{e}_{1},\boldsymbol{e}_{2}, \dots,\boldsymbol{e}_{m})\), this implies that \(R_{\log{p}}^{m}=\operatorname{span}( \boldsymbol{e}_{1},\boldsymbol{e}_{2},\dots,\boldsymbol{e}_{m})\). By Eq. (38) and Proposition 2.2, we then obtain that \(\{f(\boldsymbol{\theta})\mid\boldsymbol{\theta}\in \mathcal{D}\}\subseteq R_{\log{p}}^{m}=R_{p}^{m}\). □
For the proof of Lemma 3.1 we need the following result.
Lemma A.1
Let \(\boldsymbol{H}\in\mathbb{R}^{d\times d}\) be a symmetric matrix and define
and
where \(\{\boldsymbol{v}_{i}\}_{i=m+1}^{d}\) denote the orthonormal eigenvectors of H corresponding to its eigenvalues λ m+1≥λ m+2≥…≥λ d . If we define \(\tilde{\boldsymbol{H}}=\boldsymbol {V}^{T}\boldsymbol{H}\boldsymbol{V}\), then \(\tilde{\boldsymbol{H}}=\boldsymbol{ \varLambda}\). Furthermore, if we let \(\boldsymbol{s}\in\operatorname{span}(\boldsymbol {v}_{m+1},\boldsymbol{v}_{m+2},\dots,\boldsymbol{v}_{d})\) and \(\boldsymbol{g}\in \mathbb{R}^{d}\) and define \(\tilde{\boldsymbol{s}}=\boldsymbol{V}^{T}\boldsymbol{s }\) and
with \(\tilde{\boldsymbol{g}}=\boldsymbol{V}^{T}\boldsymbol{g}\), then we have \(Q( \boldsymbol{s})=\tilde{Q}(\tilde{\boldsymbol{s}})\), \(\|\boldsymbol{s}\|=\| \tilde{\boldsymbol{s}}\|\) and \(\boldsymbol{s}=\boldsymbol{V}\tilde{\boldsymbol {s}}\).
Proof
In order to show that \(\tilde{\boldsymbol{H}}=\boldsymbol{\varLambda}\), we define the matrices
where \(\{\boldsymbol{v}_{i}\}_{i=1}^{d}\) denote the eigenvectors of H corresponding to its eigenvalues λ 1≥λ 2≥…≥λ d . By the definition \(\tilde{\boldsymbol{H}}=\boldsymbol{V}^{T} \boldsymbol{H}\boldsymbol{V}\) and the eigendecomposition H=WUW T, we have
where e i denotes a d−m-dimensional unit vector along the i-th coordinate axis.
Since the vectors \(\{\boldsymbol{v}_{i}\}_{i=m+1}^{d}\) span an orthonormal basis, we have s=VV T s for all \(\boldsymbol{s}\in\operatorname{span}(\boldsymbol{v}_{m+1},\boldsymbol{v}_{m+2},\dots, \boldsymbol{v}_{d})\). Thus, by the definition \(\tilde{\boldsymbol{s}}= \boldsymbol{V}^{T}\boldsymbol{s}\), for any such s we obtain
and also \(\boldsymbol{s}=\boldsymbol{V}\boldsymbol{V}^{T}\boldsymbol{s}= \boldsymbol{V}\tilde{\boldsymbol{s}}\).
Finally, for \(\boldsymbol{s}\in\operatorname{span}(\boldsymbol{v}_{m+1},\boldsymbol{v }_{m+2},\dots,\boldsymbol{v}_{d})\) and \(\tilde{\boldsymbol{s}}=\boldsymbol{V}^{T} \boldsymbol{s}\), by expressing s as a linear combination of the orthonormal basis vectors \(\{\boldsymbol{v}_{i}\}_{i=1}^{d}\) that span \(\mathbb{R }^{d}\), we obtain
□
Lemma 3.1
Let \(\boldsymbol{g}\in\mathbb{R}^{d}\) and let \(\boldsymbol{H}\in\mathbb{R}^{d \times d}\) be a symmetric matrix and define
Let 0≤m<d, Δ>0 and let λ m+1≥λ m+2≥…≥λ d and \(\{\boldsymbol{v}_{i}\}_{i=m+1}^{d}\) denote the d−m smallest eigenvalues and the corresponding normalized eigenvectors of H, respectively. A vector \(\boldsymbol{s}^{*}\in\mathbb{R}^{d}\) is a solution to the problem
if s ∗ is feasible and the conditions
hold for some κ≥0, where
and I is the (d−m)×(d−m) identity matrix.
Proof
Define \(\tilde{\boldsymbol{g}}=\boldsymbol{V}^{T}\boldsymbol{g}\) and \(\tilde{ \boldsymbol{H}}=\boldsymbol{V}^{T}\boldsymbol{H}\boldsymbol{V}\). By Theorem 4.1 of [27], a vector \(\tilde{\boldsymbol{s}}^{*}\in\mathbb{R}^{d-m}\) is a solution to the problem
where
if
for some κ≥0.
Assume then that \(\boldsymbol{s}^{*}\in\mathbb{R}^{d}\) is in the feasible set of problem (43), that is, \(\boldsymbol{s}^{*}\in\operatorname{span}( \boldsymbol{v}_{m+1},\boldsymbol{v}_{m+2},\dots,\boldsymbol{v}_{d})\) and ∥s ∗∥≤Δ. In addition, assume that conditions (44)–(46) are satisfied with some κ≥0. Let \(\tilde{\boldsymbol{s}}^{*}=\boldsymbol{V}^{T} \boldsymbol{s}\). By Lemma A.1 we have \(\tilde{ \boldsymbol{H}}=\boldsymbol{\varLambda}\). Thus, by premultiplying condition (44) by V T we obtain \((\tilde{ \boldsymbol{H}}-\kappa\boldsymbol{I})\boldsymbol{V}^{T}\boldsymbol{s}^{*}=- \boldsymbol{V}^{T}\boldsymbol{g}\). By the definitions of \(\tilde{\boldsymbol{s} }^{*}\) and \(\tilde{\boldsymbol{g}}\), this is equivalent to condition (48). In addition, since by Lemma A.1 we have \(\|\boldsymbol{s}^{*}\|=\|\tilde{ \boldsymbol{s}}^{*}\|\), condition (45) implies condition (49) and the condition that \(\|\tilde {\boldsymbol{s}}\|\leq\varDelta\). Finally, since the matrices V(Λ−κ I)V T and Λ−κ I have the same nonzero eigenvalues and \(\boldsymbol{\varLambda}=\tilde{\boldsymbol{H}}\) by Lemma A.1, condition (46) implies condition (50). Hence, \(\tilde{ \boldsymbol{s}}^{*}\) is a solution to problem (47).
By Lemma A.1 we have \(Q(\boldsymbol{s}^{*})=\tilde{Q} (\tilde{\boldsymbol{s}}^{*})\). Assume then that there exists \(\boldsymbol{u}\in \mathbb{R}^{d}\) that is in the feasible set of problem (43) such that Q(u)>Q(s ∗). By Lemma A.1, this implies that \(Q(\boldsymbol{u})=\tilde {Q}(\tilde{\boldsymbol{u}})>\tilde{Q}(\tilde{\boldsymbol{s}}^{*})=Q(\boldsymbol {s}^{*})\), where \(\tilde{\boldsymbol{u}}=\boldsymbol{V}^{T}\boldsymbol{u}\). This leads to a contradiction with the above fact that \(\tilde{\boldsymbol{s} }^{*}\) is a solution to problem (47), and thus s ∗ is a solution to problem (43). □
Finally, we prove Lemma 3.6.
Lemma 3.6
Let the sequences {x k } and {ρ k } be generated by Algorithm 1. If \(\boldsymbol{x}_{k}\notin\tilde{R }_{\hat{p}}^{m}\) and \(\rho_{k}\leq\frac{1}{10}\) for some index k, then there exists an index k 0>k such that \(\rho_{k'}>\frac{1}{10}\) for all k′≥k 0.
Proof
Assume by contradiction that for some k we have \(\rho_{k'}\leq\frac{1}{10}\) for all k′≥k. By Eqs. (10), (28) and the fact that \(Q_{k'}(\boldsymbol{0})= \hat{p}(\boldsymbol{x}_{k'})\) we obtain
for all k′. On the other hand, by Lemma 3.2 the superlevel set \(\mathcal{L}_{\hat{p}(\boldsymbol{x})}\) is compact for any \(\boldsymbol{x}\in\mathbb{R}^{d}\). Thus, since \(\hat{p}\) is a C ∞-function, we can choose a point \(\boldsymbol{z}\in\mathbb{R}^{d}\) such that the Hessian \(\nabla^{2}\hat{p}\) is locally Lipschitz-continuous with some Lipschitz constant L>0 on the compact set \(\mathcal{L}_{\hat{p}(\boldsymbol{ z})}\) whose interior contains x k . Hence, for the numerator of Eq. (51) we obtain the Taylor series estimate (see e.g. [14], Theorem 1.1)
that holds when \(\boldsymbol{x}_{k'}+\boldsymbol{s}_{k'}\in\mathcal{L}_{\hat{ p}(\boldsymbol{z})}\). On the other hand, by Lemma 3.3 Eq. (31) holds, and thus for the denominator of Eq. (51) we have
for all k′≥k with some \(\boldsymbol{R}_{k'}\in\mathbb{R}^{(d-m)\times (d-m)}\).
By the assumption that \(\rho_{k'}\leq\frac{1}{10}\) for all k′≥k, we have lim k′→∞ Δ k′=0 by the updating rules (11) and x k′=x k for all k′≥k. Thus, there exists k 0≥k such that \(\boldsymbol{x}_{ k'}+\boldsymbol{s}_{k'}\in\mathcal{L}_{\hat{p}(\boldsymbol{z})}\) for all k′≥k 0, which implies that inequality (52) holds for all k′≥k 0. Then substituting inequalities (52) and (53) into Eq. (51) and noting that ∥s k′∥≤Δ k′ for all k′ yields
for all k′≥k 0.
The remainder of the proof is divided into two cases. If λ m+1(x k )>0, then for all k′>k we have κ k′≥λ m+1(x k′)=λ m+1(x k )>0 by condition (27) and the fact that x k′=x k for all k′≥k. Hence, by inequality (54) and the limiting value lim k′→∞ Δ k′=0 we obtain that
which leads to contradiction with the assumption that \(\rho_{k'}\leq\frac{1}{ 10}\) for all k′≥k.
On the other hand, when λ m+1(x k )≤0, it suffices to consider the case when lim κ→0∥s k (κ)∥>0, where
corresponds to Eq. (18). Otherwise, if λ m+1(x k )≤0 and lim κ→0∥s k (κ)∥=0, then \(\nabla\hat{p}(\boldsymbol{x}_{k})^{T}\boldsymbol{v}_{i}( \boldsymbol{x}_{k})=0\) for all i=m+1,m+2,…,d, and thus \(\boldsymbol{x}_{k} \in\tilde{R}_{\hat{p}}^{m}\) (and Algorithm 1 has already terminated by conditions (12)). Since x k′=x k for all k′≥k by the assumption that \(\rho_{k' }\leq\frac{1}{10}\) for all k′≥k, we observe that ∥s k′(κ)∥=∥s k (κ)∥ for all κ and k′≥k. So, if λ m+1(x k )≤0 and lim κ→0∥s k (κ)∥>0, there exists k 1≥k such that lim κ→0∥s k′(κ)∥=lim κ→0∥s k (κ)∥>Δ k′>0 for all k′≥k 1 since lim k′→∞ Δ k′=0 by the updating rules (11). Thus, since the function ∥s k′(κ)∥=∥s k (κ)∥ is continuous and monotoneously decreasing in the interval ]0,∞[, for all k′≥k 1 the equation ∥s k′(κ)∥=Δ k has a unique solution lying in the interval ]0,∞[. By these properties, if we denote such a solution by \(\kappa^{*}_{k'}\), we have \(\lim_{k'\to\infty}\kappa^{*}_{k'}= \infty\) since lim k′→∞ Δ k′=0. As stated in Sect. 3.2, at each iteration k′≥k 1 Algorithm 2 generates κ k′ as such a solution. From inequality (54) we then conclude that lim k′→∞|ρ k′−1|=0, which again leads to contradiction with the assumption that \(\rho_{k'}\leq\frac{1}{10}\) for all k′≥k. □
Rights and permissions
About this article
Cite this article
Pulkkinen, S., Mäkelä, M.M. & Karmitsa, N. A generative model and a generalized trust region Newton method for noise reduction. Comput Optim Appl 57, 129–165 (2014). https://doi.org/10.1007/s10589-013-9581-4
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-013-9581-4