
Abstract
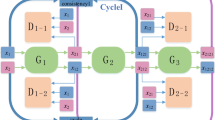
Existing methods for makeup transfer mainly focus on the transfer of facial makeup, while overlooking the importance of hairstyles. To address this issue, we propose a composite makeup transfer model based on generative adversarial networks, which cleverly achieves composite transfer of facial makeup and hairstyles. Our model consists of two parallel branches: the facial makeup transfer branch and the hairstyle transfer branch. The facial makeup transfer branch integrates semantic correspondence learning and utilizes a bidirectional semantic correspondence feature transfer module to model and promote accurate semantic correspondence. During the generation process, we spatially distort the extracted makeup features to achieve semantic alignment with the target image. Subsequently, we fuse the distorted makeup features with the unmodified makeup-irrelevant features to generate facial makeup transfer results. In the hairstyle transfer branch, we introduce a occlusion repair module. This module leverages semantic relationships to repair facial occlusions in the source image. Then, combined with the pose consistency module, it generates hairstyle transfer results. Finally, the overall model’s generation effect is regulated through the comprehensive loss function we propose. Experimental results demonstrate that our method achieves visually accurate composite makeup and hairstyle transfer results.











Similar content being viewed by others


Data availability
The CelebA-HQ dataset and FFHQ dataset for the current study period are available in the [OpenDataLab] repositories [ https://opendatalab.com/OpenDataLab/CelebA-HQ ] and [ https://opendata-lab.com/OpenData-Lab/FFHQ ].
References
Ali, A., Touvron, H., Caron, M., Bojanowski, P., Douze, M., Joulin, A., Laptev, I., Neverova, N., Synnaeve, G., Verbeek, J., et al.: Xcit: Cross-covariance image transformers. Adv. Neural Inform. Process. Syst. 34, 20014–20027 (2021)
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In Seminal Graphics Papers: Pushing the Boundaries 2, 157–164 (2023)
Adrian, B., Georgios, T.: How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE international conference on computer vision, pages 1021–1030 (2017)
Chaeyeon, C., Taewoo, K., Hyelin, N., Seunghwan, C., Gyojung, G., Sunghyun, P., Jaegul, C.: Hairfit: pose-invariant hairstyle transfer via flow-based hair alignment and semantic-region-aware inpainting. arXiv preprint arXiv:2206.08585 (2022)
Han, D., Chu, H., Hongmin, C., Guoqiang, H., Shengfeng, H.: Spatially-invariant style-codes controlled makeup transfer. In: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 6549–6557 (2021)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Bing, X., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Yoshua: Generative adversarial networks. Commun. ACM 63(11), 139–144 (2020)
Dong, G., Terence, S. (2009) Digital face makeup by example. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 73–79. IEEE
Xuyang, G., Meina, K., Zhenliang, H., Xingguang, S., Shiguang, S.: Image style disentangling for instance-level facial attribute transfer. volume 207, page 103205. Elsevier (2021)
Xun, H., Ming-Yu, L., Serge, B., Jan, K. Multimodal unsupervised image-to-image translation. In Proceedings of the European conference on computer vision (ECCV), pages 172–189 (2018)
Jia, D., Cao, J., Pan, J., Pang, Y.: Multi-stream densely connected network for semantic segmentation. IET Comput Vis 16(2), 180–191 (2022)
Wentao, J., Si, L., Chen, G., Jie, C., Ran, H., Jiashi, F., Shuicheng, Y. Psgan: Pose and expression robust spatial-aware gan for customizable makeup transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5194–5202 (2020)
Youngjoo, J., Jongyoul, P. Sc-fegan: Face editing generative adversarial network with user’s sketch and color. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1745–1753 (2019)
Tero, K., Samuli, L., Timo, A. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410 (2019)
Tero, K., Samuli, L., Miika, A., Janne, H., Jaakko, L., Timo, A. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8110–8119 (2020)
Taewoo, K., Chaeyeon, C., Yoonseo, K., Sunghyun, P., Kangyeol, K., Jaegul, C. Style your hair: Latent optimization for pose-invariant hairstyle transfer via local-style-aware hair alignment. In European Conference on Computer Vision, pages 188–203. Springer (2022)
Hsin-Ying, L., Hung-Yu, T., Jia-Bin, H., Maneesh, S., Ming-Hsuan, Y. Diverse image-to-image translation via disentangled representations. In Proceedings of the European conference on computer vision (ECCV), pages 35–51 (2018)
Chen, L., Kun, Z., Stephen, L. Simulating makeup through physics-based manipulation of intrinsic image layers. In Proceedings of the IEEE Conference on computer vision and pattern recognition, pages 4621–4629 (2015)
Si, L., Xinyu, O., Ruihe, Q., Wei, W., Xiaochun, C. Makeup like a superstar: Deep localized makeup transfer network. arXiv preprint arXiv:1604.07102 (2016)
Taesung, P., Ming-Yu, L., Ting-Chun, W., Jun-Yan, Z. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2337–2346 (2019)
Tiziano, P., Qiyang, H., Attila, S., Siavash Arjomand, B., Paolo, F., Matthias, Z. Faceshop: Deep sketch-based face image editing. arXiv preprint arXiv:1804.08972 (2018)
Ren, Y., Huang, Z.: Distribution probability-based self-adaption metric learning for person re-identification. IET Comput Vis 16(4), 376–387 (2022)
Rohit, S., Brendan, D., Florian, S., Taylor Graham, W., Parham, A. (2021) Loho: Latent optimization of hairstyles via orthogonalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1984–1993
Kristina, S., Tobias, R., Matthias, H., Thorsten, T. Volker, B., Hans-Peter, S. Computer-suggested facial makeup. In Computer Graphics Forum, volume 30, pages 485–492. Wiley Online Library (2011)
Karen, S., Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Sun, Z., Chen, Y., Xiong, S.: Ssat: A symmetric semantic-aware transformer network for makeup transfer and removal. Proc. AAAI Conf. Artificial Intell. 36, 2325–2334 (2022)
Zhentao, T., Menglei, C., Dongdong, C., Jing, L., Qi, C., Lu, Y., Sergey, T., Nenghai, Y Michigan: multi-input-conditioned hair image generation for portrait editing. arXiv preprint arXiv:2010.16417 (2020)
Wai-Shun, T., Chi-Keung, T., Brown Michael, S., Ying-Qing, X.Example-based cosmetic transfer. In 15th Pacific Conference on Computer Graphics and Applications (PG’07), pages 211–218. IEEE (2007)
Wang, C., Ning, X., Sun, L., Zhang, L., Li, W., Bai, Xiao: Learning discriminative features by covering local geometric space for point cloud analysis. IEEE Trans. Geosci. Remote Sens. 60, 1–15 (2022)
Shuai, Y., Zhangyang, W., Jiaying, L., Zongming, G. Deep plastic surgery: Robust and controllable image editing with human-drawn sketches. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16, pages 601–617. Springer (2020)
Chengyao, Z., Siyu, X., Ming, S., Yun, F.: Fast facial image analogy with spatial guidance. In 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pages 1–5. IEEE (2019)
Mingrui, Z., Yun, Y., Nannan, W., Xiaoyu, W., Xiaoyu, G.,: Semi-parametric makeup transfer via semantic-aware correspondence. arXiv preprint arXiv:2203.02286 (2022)
Peihao, Z., Rameen, A., John, F., Peter, W.: Barbershop: Gan-based image compositing using segmentation masks. arXiv preprint arXiv:2106.01505 (2021)
Funding
This work is supported by the National Natural Science Foundation project “Research on Intelligent Scheduling Method of Cloud and Fog Resources in Mine Safety Control Linkage System“; Anhui University of Science and Technology 2023 Graduate Student Innovation Fund project “Research on Makeup transfer Network Integrating multi-modal emotional Features” and Medical Cross Fund project “Multimodal adaptive Double U-shaped polyp segmentation and registration algorithm for colonoscopy” (Grant No [52374154], [2023cx2126] and [YZ2023H2B001]).
Author information
Authors and Affiliations
Contributions
All authors contributed to the conception and design of the study. Material preparation, data collection and analysis were carried out by [YP], [KS] and [HZ]. The first draft of the manuscript was written by [YP], and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The author has no relevant financial or non-financial interests to disclose.
Additional information
Communicated by Yongdong Zhang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sun, K., Pan, Y. & Zhou, H. Composite makeup transfer model based on generative adversarial networks. Multimedia Systems 30, 301 (2024). https://doi.org/10.1007/s00530-024-01516-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01516-4