
Abstract
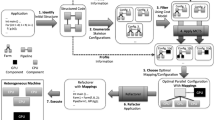
This paper describes the ParaPhrase project, a new 3-year targeted research project funded under EU Framework 7 Objective 3.4 (Computer Systems), starting in October 2011. ParaPhrase aims to follow a new approach to introducing parallelism using advanced refactoring techniques coupled with high-level parallel design patterns. The refactoring approach will use these design patterns to restructure programs defined as networks of software components into other forms that are more suited to parallel execution. The programmer will be aided by high-level cost information that will be integrated into the refactoring tools. The implementation of these patterns will then use a well-understood algorithmic skeleton approach to achieve good parallelism.
A key ParaPhrase design goal is that parallel components are intended to match heterogeneous architectures, defined in terms of CPU/GPU combinations, for example. In order to achieve this, the ParaPhrase approach will map components at link time to the available hardware, and will then re-map them during program execution, taking account of multiple applications, changes in hardware resource availability, the desire to reduce communication costs etc. In this way, we aim to develop a new approach to programming that will be able to produce software that can adapt to dynamic changes in the system environment. Moreover, by using a strong component basis for parallelism, we can achieve potentially significant gains in terms of reducing sharing at a high level of abstraction, and so in reducing or even eliminating the costs that are usually associated with cache management, locking, and synchronisation.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Adve, S., Adve, V., Agha, G., Frank, M., et al.: Parallel@Illinois: Parallel Computing Research at Illinois — The UPCRC Agenda (November 2008), http://www.upcrc.illinois.edu/documents/UPCRC_Whitepaper.pdf
Aldinucci, M., Campa, S., Danelutto, M., Vanneschi, M., Dazzi, P., Laforenza, D., Tonellotto, N., Kilpatrick, P.: Behavioural skeletons in GCM: autonomic management of grid components. In: Euromicro PDP 2008, Toulouse, pp. 54–63. IEEE (February 2008)
Aldinucci, M., Danelutto, M., Dazzi, P.: MUSKEL: an expandable skeleton environment. Scalable Computing: Practice and Experience 8(4), 325–341 (2007)
Aldinucci, M., Danelutto, M., Kilpatrick, P.: Autonomic management of non-functional concerns in distributed and parallel application programming. In: IPDPS 2009, Rome, pp. 1–12. IEEE (May 2009)
Aldinucci, M., Danelutto, M., Kilpatrick, P.: Autonomic management of multiple non-functional concerns in behavioural skeletons. In: Desprez, F., Getov, V., Priol, T., Yahyapour, R. (eds.) Grids, P2P and Services Computing, pp. 89–103. Springer (2010)
Allen, R., Kennedy, K.: Optimizing Compilers for Modern Architectures. Morgan Kaufmann Publishers (2001) ISBN 1-55860-286-0
Asanovic, K., Bodik, R., Demmel, J., Keaveny, T., Keutzer, K., Kubiatowicz, J., Morgan, N., Patterson, D., Sen, K., Wawrzynek, J., Wessel, D., Yelick, K.: A view of the parallel computing landscape. Communications of the ACM 52(10), 56–67 (2009)
Bacon, D., Graham, S., Sharp, O.: Compiler Transformations for High-Performance Computing. ACM Computing Surveys 26(4), 345–420 (1994)
Bastoul, C.: Code generation in the polyhedral model is easier than you think. In: PACT’13 IEEE International Conference on Parallel Architecture and Compilation Techniques, Juan-les-Pins, France, pp. 7–16 (September 2004)
Bernecky, R., Herhut, S., Scholz, S.-B., Trojahner, K., Grelck, C., Shafarenko, A.: Index Vector Elimination – Making Index Vectors Affordable. In: Horváth, Z., Zsók, V., Butterfield, A. (eds.) IFL 2006. LNCS, vol. 4449, pp. 19–36. Springer, Heidelberg (2007)
Bharadwaj, V., Ghose, D., Mani, V., Robertazzi, T.G.: Scheduling Divisible Loads in Parallel and Distributed Systems. IEEE, Los Alamitos (1996)
Bondhugula, U., Hartono, A., Ramanujam, J., Sadayappan, P.: A practical automatic polyhedral parallelizer and locality optimizer. In: PLDI 2008: Proceedings of the 2008 ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 101–113. ACM, New York (2008)
Buono, D., Danelutto, M., Lametti, S.: Map, reduce and mapreduce, the skeleton way. Procedia CS 1(1), 2095–2103 (2010)
Casanova, H., Kim, M.-H., Plank, J.S., Dongarra, J.: Adaptive scheduling for task farming with grid middleware. Int. J. High Perform. Comput. Appl. 13(3), 231–240 (1999)
Casavant, T., Kuhl, J.: A taxonomy of scheduling in general-purpose distributed computing systems. IEEE Trans. Softw. Eng. 14(2), 141–154 (1988)
Chu, C.-T., Kim, S.K., Lin, Y.-A., Ng, A.Y.: Map-reduce for machine learning on multicore. Architecture 19(23), 281 (2007)
Cole, M.: Algorithmic Skeletons: Structured Management of Parallel Computation. Research Monographs in Parallel and Distributed Computing. Pitman/MIT Press, London (1989)
Danelutto, M.: On Skeletons and Design Patterns. In: Joubert, G.H., Murli, A., Peters, F.J., Vanneschi, M. (eds.) PARALLEL COMPUTING Advances and Current Issues Proceedings of the International Conference ParCo 2001. Imperial College Press (2002) ISBN: 1860943152
Danelutto, M.: HPC the easy way: new technologies for high performance application development and deployment. Journal of Systems Architecture 49(10-11), 399–419 (2003)
Dig, D.: A refactoring approach to parallelism. IEEE Softw. 28, 17–22 (2011)
El-Rewini, H., Lewis, T.G., Ali, H.H.: Task Scheduling in Parallel and Distributed Systems. Innovative Technology Series. Prentice Hall, New Jersey (1994)
Feautrier, P.: Some efficient solutions to the affine scheduling problem: I. one-dimensional time. Int. J. Parallel Program. 21(5), 313–348 (1992)
Feautrier, P.: Automatic Parallelization in the Polytope Model. In: Perrin, G.-R., Darte, A. (eds.) The Data Parallel Programming Model. LNCS, vol. 1132, pp. 79–103. Springer, Heidelberg (1996)
Eclipse Foundation: Eclipse - an Open Development Platform (2009), http://www.eclipse.org
Gamma, E., Helm, R., Johnson, R., Vlissides, J.: Design Patterns: Abstraction and Reuse of Object-Oriented Design. In: Nierstrasz, O.M. (ed.) ECOOP 1993. LNCS, vol. 707, pp. 406–431. Springer, Heidelberg (1993)
Gamma, E., Helm, R., Johnson, R., Vlissides, J.M.: Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional Computing Series. Addison-Wesley, Upper Saddle River (1995)
Geppert, L., Perry, T.S.: Transmeta’s magic show (microprocessor chips). IEEE Spectrum (2000)
Gillick, D., Faria, A., DeNero, J.: Mapreduce: Distributed computing for machine learning, Berkley (December 18, 2006)
González-Vélez, H., Cole, M.: An adaptive parallel pipeline pattern for grids. In: IPDPS 2008, Miami, USA, pp. 1–11. IEEE (April 2008)
González-Vélez, H., Cole, M.: Adaptive statistical scheduling of divisible workloads in heterogeneous systems. Journal of Scheduling 13(4), 427–441 (2010)
González-Vélez, H., Cole, M.: Adaptive structured parallelism for distributed heterogeneous architectures: A methodological approach with pipelines and farms. Concurrency and Computation–Practice & Experience 22(15), 2073–2094 (2010)
González-Vélez, H., Leyton, M.: A survey of algorithmic skeleton frameworks: High-level structured parallel programming enablers. Software–Practice & Experience 40(12), 1135–1160 (2010)
Grelck, C.: Shared memory multiprocessor support for functional array processing in SAC. Journal of Functional Programming 15(3), 353–401 (2005)
Grelck, C., Hinckfuß, K., Scholz, S.-B.: With-Loop Fusion for Data Locality and Parallelism. In: Butterfield, A., Grelck, C., Huch, F. (eds.) IFL 2005. LNCS, vol. 4015, pp. 178–195. Springer, Heidelberg (2006)
Grelck, C., Kuthe, S., Scholz, S.-B.: A Hybrid Shared Memory Execution Model for a Data Parallel Language with I/O. Parallel Processing Letters 18(1), 23–37 (2008)
Grelck, C., Scholz, S.-B., Shafarenko, A.: A Binding Scope Analysis for Generic Programs on Arrays. In: Butterfield, A., Grelck, C., Huch, F. (eds.) IFL 2005. LNCS, vol. 4015, pp. 212–230. Springer, Heidelberg (2006)
Grelck, C., Scholz, S.-B., Trojahner, K.: With-Loop Scalarization – Merging Nested Array Operations. In: Trinder, P., Michaelson, G., Peña, R. (eds.) IFL 2003. LNCS, vol. 3145, pp. 118–134. Springer, Heidelberg (2004)
Griebl, M.: Automatic Parallelization of Loop Programs for Distributed Memory Architectures. University of Passau (2004) (Habilitation thesis)
Herhut, S., Scholz, S.-B., Bernecky, R., Grelck, C., Trojahner, K.: From Contracts Towards Dependent Types: Proofs by Partial Evaluation. In: Chitil, O., Horváth, Z., Zsók, V. (eds.) IFL 2007. LNCS, vol. 5083, pp. 254–273. Springer, Heidelberg (2008)
Kennedy, K., McKinley, K.S., Tseng, C.W.: Interactive parallel programming using the parascope editor. IEEE Trans. Parallel Distrib. Syst. 2, 329–341 (1991)
Kruskal, C., Weiss, A.: Allocating independent subtasks on parallel processors. IEEE Transactions on Software Engineering SE-11(10), 1001–1016 (1985)
Lengauer, C.: Loop Parallelization in the Polytope Model. In: Best, E. (ed.) CONCUR 1993. LNCS, vol. 715, pp. 398–416. Springer, Heidelberg (1993)
Leonard, P.: The Multi-Core Dilemma, Intel Software Blog (March 2007), http://software.intel.com/en-us/blogs/2007/03/14/the-multi-core-dilemma-by-patrick-leonard/
Lim, A.W., Lam, M.S.: Maximizing parallelism and minimizing synchronization with affine transforms - extended journal version parallel computing. Parallel Computing (1998)
Lim, A.W., Liao, S.-W., Lam, M.S.: Blocking and array contraction across arbitrarily nested loops using affine partitioning. In: PPoPP 2001: Proceedings of the Eighth ACM SIGPLAN Symposium on Principles and Practices of Parallel Programming, pp. 103–112. ACM, New York (2001)
Lindholm, T., Yellin, F.: The Java Virtual Machine Specification. Prentice Hall (1999)
Long, S., O’Boyle, M.: Adaptive java optimisation using instance-based learning. In: ICS 2004: Proceedings of the 18th Annual International Conference on Supercomputing, pp. 237–246. ACM, New York (2004)
Low, Y., Gonzalez, J., Kyrola, A., Bickson, D., Guestrin, C., Hellerstein, J.M.: Graphlab: A new framework for parallel machine learning. CoRR, abs/1006.4990 (2010)
Majumdar, S., Eager, D.L., Bunt, R.B.: Scheduling in multiprogrammed parallel systems. SIGMETRICS Perform. Eval. Rev. 16(1), 104–113 (1988)
Mattson, T.G., Sanders, B.A., Massingill, B.L.: Patterns for Parallel Programming. Software Patterns Series. Addison-Wesley, Boston (2004)
Opdyke, W.F.: Refactoring object-oriented frameworks. PhD thesis, UIUC, Champaign, IL, USA (1992)
Owens, J., Houston, M., Luebke, D., Green, S., Stone, J., Phillips, J.: GPU computing. Proceedings of the IEEE 96(5), 879–899 (2008)
Pop, A., Pop, S., Sjödin, J.: Automatic streamization in GCC. In: Proc. of the 2009 GCC Developers Summit, Montréal, Canada (June 2009)
Pouchet, L.-N., Bastoul, C., Cohen, A., Cavazos, J.: Iterative optimization in the polyhedral model: part ii, multidimensional time. In: PLDI 2008: Proceedings of the 2008 ACM SIGPLAN Conference on Programming Language Design and Implementation, pp. 90–100. ACM, New York (2008)
Rabhi, F.A., Gorlatch, S. (eds.): Patterns and Skeletons for Parallel and Distributed Computing. Springer, London (2003)
Scholz, S.-B.: With-Loop-Folding in Sac - Condensing Consecutive Array Operations. In: Clack, C., Hammond, K., Davie, T. (eds.) IFL 1997. LNCS, vol. 1467, pp. 72–91. Springer, Heidelberg (1998)
Shao, G., Berman, F., Wolski, R.: Master/slave computing on the grid. In: HCW 2000, Cancun, pp. 3–16. IEEE (May 2000)
Tamano, H., Nakadai, S., Araki, T.: Optimizing multiple machine learning jobs on mapreduce. In: 2011 IEEE Third International Conference on Cloud Computing Technology and Science, CloudCom, November 29-December 1, pp. 59–66 (2011)
Trojahner, K., Grelck, C., Scholz, S.-B.: On Optimising Shape-Generic Array Programs Using Symbolic Structural Information. In: Horváth, Z., Zsók, V., Butterfield, A. (eds.) IFL 2006. LNCS, vol. 4449, pp. 1–18. Springer, Heidelberg (2007)
University of Mannheim, University of Tennessee and NERSC. TOP500 supercomputer sites (November 2010), http://www.top500.org/ (last accessed: December 1, 2010)
Vadhiyar, S.S., Dongarra, J.: Self adaptivity in grid computing. Concurr. Comput.-Pract. Exp. 17(2-4), 235–257 (2005)
Wloka, J., Sridharan, M., Tip, F.: Refactoring for reentrancy. In: ESEC/FSE 2009, pp. 173–182. ACM, Amsterdam (2009)
Wolfe, M.: High-Performance Compilers for Parallel Computing. Addison-Wesley (1995) ISBN 0-8053-2730-4
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Hammond, K. et al. (2013). The ParaPhrase Project: Parallel Patterns for Adaptive Heterogeneous Multicore Systems. In: Beckert, B., Damiani, F., de Boer, F.S., Bonsangue, M.M. (eds) Formal Methods for Components and Objects. FMCO 2011. Lecture Notes in Computer Science, vol 7542. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-35887-6_12
Download citation
DOI: https://doi.org/10.1007/978-3-642-35887-6_12
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-35886-9
Online ISBN: 978-3-642-35887-6
eBook Packages: Computer ScienceComputer Science (R0)