
Abstract
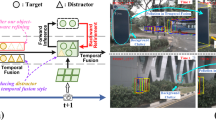
Long-term temporal fusion is frequently employed in camera-based Bird’s-Eye-View (BEV) 3D object detection to improve detection of occluded objects. Existing methods can be divided into two categories, parallel fusion and recurrent fusion. Recurrent fusion reduces inference latency and memory consumption but fails to exploit the long-term information as well as parallel fusion. In this paper, we first find two shortcomings of recurrent fusion paradigm: (1) Gradients of previous BEV features cannot directly contribute to the fusion module. (2) Semantic ambiguity are caused by coarse granularity of the BEV grids during aligning BEV features. Then based on the above analysis, we propose RecurrentBEV, a novel recurrent temporal fusion method for BEV based 3D object detector. By adopting RNN-style back-propagation and new-designed inner grid transformation, RecurrentBEV improves the long-term fusion ability while still enjoying efficient inference latency and memory consumption during inference. Extensive experiments on the nuScenes benchmark demonstrate its effectiveness, achieving a new state-of-the-art performance of 57.4\(\%\) mAP and 65.1\(\%\) NDS on the test set. The real-time version (25.6 FPS) achieves 44.5\(\%\) mAP and 54.9\(\%\) NDS without external dataset, outperforming the previous best method StreamPETR by 1.3\(\%\) mAP and 0.9\(\%\) NDS. The code is available at https://github.com/lucifer443/RecurrentBEV.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Details of evaluation metrics: https://www.nuscenes.org/object-detection.
- 2.
Similar performance to VideoBEV [8] without stereo matching (VideoBEV-D) with 60 training epochs.
References
Ballas, N., Yao, L., Pal, C., Courville, A.: Delving deeper into convolutional networks for learning video representations. In: ICLR (2016)
Caesar, H., et al.: nuScenes: a multimodal dataset for autonomous driving. In: CVPR (2020)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: ECCV (2020)
Chen, D., Li, J., Guizilini, V., Ambrus, R.A., Gaidon, A.: Viewpoint equivariance for multi-view 3D object detection. In: CVPR (2023)
Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE TPAMI 40(4), 834–848 (2017)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: CVPR (2009)
Feng, C., Jie, Z., Zhong, Y., Chu, X., Ma, L.: Aedet: azimuth-invariant multi-view 3D object detection. In: CVPR (2023)
Han, C., et al.: Exploring recurrent long-term temporal fusion for multi-view 3D perception. arXiv preprint arXiv:2303.05970 (2023)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Huang, B., et al.: Fast-bev: towards real-time on-vehicle bird’s-eye view perception. arXiv preprint arXiv:2301.07870 (2023)
Huang, J., Huang, G.: Bevdet4d: exploit temporal cues in multi-camera 3D object detection. arXiv preprint arXiv:2203.17054 (2022)
Huang, J., Huang, G.: Bevpoolv2: a cutting-edge implementation of bevdet toward deployment. arXiv preprint arXiv:2211.17111 (2022)
Huang, J., Huang, G., Zhu, Z., Ye, Y., Du, D.: Bevdet: high-performance multi-camera 3D object detection in bird-eye-view. arXiv preprint arXiv:2112.11790 (2021)
Huang, L., et al.: Leveraging vision-centric multi-modal expertise for 3D object detection. In: NeurIPS (2023)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: NeurIPS (2015)
Jiang, Y., et al.: Polarformer: multi-camera 3D object detection with polar transformer. In: AAAI (2023)
Lee, Y., Hwang, J.W., Lee, S., Bae, Y., Park, J.: An energy and GPU-computation efficient backbone network for real-time object detection. In: CVPRW (2019)
Li, H., et al.: DFA3D: 3D deformable attention for 2D-to-3D feature lifting. In: ICCV (2023)
Li, Y., Chen, Y., Qi, X., Li, Z., Sun, J., Jia, J.: Unifying voxel-based representation with transformer for 3D object detection. In: NeurIPS (2022)
Li, Y., Bao, H., Ge, Z., Yang, J., Sun, J., Li, Z.: Bevstereo: enhancing depth estimation in multi-view 3D object detection with temporal stereo. In: AAAI (2023)
Li, Y., et al.: Bevdepth: acquisition of reliable depth for multi-view 3D object detection. In: AAAI (2023)
Li, Z., et al.: Bevformer: lbird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In: ECCV (2022)
Li, Z., Yu, Z., Wang, W., Anandkumar, A., Lu, T., Alvarez, J.M.: FB-BEV: BEV representation from forward-backward view transformations. In: ICCV (2023)
Lin, T.Y., et al.: Microsoft coco: common objects in context. In: ECCV (2014)
Lin, X., Lin, T., Pei, Z., Huang, L., Su, Z.: Sparse4d: multi-view 3D object detection with sparse spatial-temporal fusion. arXiv preprint arXiv:2211.10581 (2022)
Lin, X., Lin, T., Pei, Z., Huang, L., Su, Z.: Sparse4d v2: recurrent temporal fusion with sparse model. arXiv preprint arXiv:2305.14018 (2023)
Liu, H., Teng, Y., Lu, T., Wang, H., Wang, L.: Sparsebev: high-performance sparse 3D object detection from multi-camera videos. In: ICCV (2023)
Liu, Y., Wang, T., Zhang, X., Sun, J.: Petr: position embedding transformation for multi-view 3D object detection. In: ECCV (2022)
Liu, Y., et al.: PETRV2: a unified framework for 3D perception from multi-camera images. In: ICCV (2023)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: CVPR (2022)
Luo, Z., Zhou, C., Zhang, G., Lu, S.: DETR4D: direct multi-view 3D object detection with sparse attention. arXiv preprint arXiv:2212.07849 (2022)
Park, D., Ambrus, R., Guizilini, V., Li, J., Gaidon, A.: Is pseudo-lidar needed for monocular 3D object detection? In: ICCV (2021)
Park, J., et al.: Time will tell: new outlooks and a baseline for temporal multi-view 3D object detection. In: ICLR (2023)
Philion, J., Fidler, S.: Lift, splat, shoot: encoding images from arbitrary camera rigs by implicitly unprojecting to 3D. In: ECCV (2020)
Wang, S., Liu, Y., Wang, T., Li, Y., Zhang, X.: Exploring object-centric temporal modeling for efficient multi-view 3D object detection. In: ICCV (2023)
Wang, Y., Guizilini, V.C., Zhang, T., Wang, Y., Zhao, H., Solomon, J.: DETR3D: 3D object detection from multi-view images via 3D-to-2D queries. In: Conference on Robot Learning (2022)
Wang, Z., Huang, Z., Fu, J., Wang, N., Liu, S.: Object as query: lifting any 2D object detector to 3D detection. In: ICCV (2023)
Xiong, K., et al.: Cape: camera view position embedding for multi-view 3D object detection. In: CVPR (2023)
Yang, C., et al.: Bevformer V2: adapting modern image backbones to bird’s-eye-view recognition via perspective supervision. In: CVPR (2023)
Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3D object detection and tracking. In: CVPR (2021)
Zhang, J., Zhang, Y., Liu, Q., Wang, Y.: SA-BEV: generating semantic-aware bird’s-eye-view feature for multi-view 3D object detection. In: ICCV (2023)
Zhou, H., Ge, Z., Li, Z., Zhang, X.: Matrixvt: efficient multi-camera to BEV transformation for 3D perception. In: ICCV (2023)
Zhu, B., Jiang, Z., Zhou, X., Li, Z., Yu, G.: Class-balanced grouping and sampling for point cloud 3D object detection. arXiv preprint arXiv:1908.09492 (2019)
Acknowledgements
This work is partially supported by the National Key R&D Program of China (under Grant 2023YFB4502200), the NSF of China (under Grants U22A2028, 61925208, 62102399, 62222214, 62341411, 62102398, U20A20227, 62372436, 623-02478, 62302482, 62302483, 62302480), Strategic Priority Research Program of the Chinese Academy of Sciences, (Grant No. XDB0660200, XDB0660201, XDB0660202), CAS Project for Young Scientists in Basic Research (YSBR-029), Youth Innovation Promotion Association CAS and Xplore Prize.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Chang, M., Zhang, X., Zhang, R., Zhao, Z., He, G., Liu, S. (2025). RecurrentBEV: A Long-Term Temporal Fusion Framework for Multi-view 3D Detection. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds) Computer Vision – ECCV 2024. ECCV 2024. Lecture Notes in Computer Science, vol 15130. Springer, Cham. https://doi.org/10.1007/978-3-031-73220-1_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-73220-1_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-73219-5
Online ISBN: 978-3-031-73220-1
eBook Packages: Computer ScienceComputer Science (R0)