
Abstract
Temporal action localization aims to localize segments in an untrimmed video that contains different actions. Since contexts at boundaries between action instances and backgrounds are similar, how to separate the action instances from their surrounding is a challenge to be solved. In fact, the similar or dissimilar contents in actions play an important role in accomplishing the task. Intuitively, the instances with the same class label are affinitive while those with different labels are divergent. In this paper, we propose a novel method to model the relations between pairs of frames and generate precise action boundaries based on the relations, namely Centroid Radiation Network (CRNet). Specifically, we propose a Relation Network (RelNet) to represent the relations between sampled pairs of frames by employing an affinity matrix. To generate action boundaries, we use an Offset Network (OffNet) to estimate centroids of each action segments and their corresponding class labels. Based on the assumption that a centroid and its propagating areas have the same action label, we obtain action boundaries by adopting random walk to propagate a centroid to its related areas. Our proposed method is an one-stage method and can be trained in an end-to-end fashion. Experimental results show that our approach outperforms the state-of-the-art methods on THUMOS14 and ActivityNet.
This work was supported in part by the National Key Research and Development Program of China under Grant 2018AAA0103202; in part by the National Natural Science Foundation of China under Grant Grants 62036007, 61922066, 61876142, 61772402, and 62050175; in part by the Xidian University Intellifusion Joint Innovation Laboratory of Artificial Intelligence; in part by the Fundamental Research Funds for the Central Universities. Student Paper.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


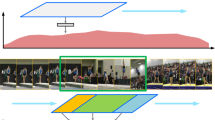
References
Buch, S., Escorcia, V., Ghanem, B., Fei-Fei, L., Niebles, J.C.: End-to-end, single-stream temporal action detection in untrimmed videos. In: Proceedings of the British Machine Vision Conference, vol. 2, p. 7 (2017)
Caba Heilbron, F., Escorcia, V., Ghanem, B., Carlos Niebles, J.: Activitynet: a large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 961–970 (2015)
Duan, X., Huang, W., Gan, C., Wang, J., Zhu, W., Huang, J.: Weakly supervised dense event captioning in videos. In: Proceedings of Advances in Neural Information Processing Systems, pp. 3059–3069 (2018)
Fan, L., Huang, W., Gan, C., Ermon, S., Gong, B., Huang, J.: End-to-end learning of motion representation for video understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6016–6025 (2018)
Gan, C., Gong, B., Liu, K., Su, H., Guibas, L.J.: Geometry guided convolutional neural networks for self-supervised video representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5589–5597 (2018)
Gan, C., Wang, N., Yang, Y., Yeung, D.Y., Hauptmann, A.G.: Devnet: a deep event network for multimedia event detection and evidence recounting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2568–2577 (2015)
Gan, C., Yang, Y., Zhu, L., Zhao, D., Zhuang, Y.: Recognizing an action using its name: a knowledge-based approach. Int. J. Comput. Vis. 120(1), 61–77 (2016)
Gan, C., Yao, T., Yang, K., Yang, Y., Mei, T.: You lead, we exceed: labor-free video concept learning by jointly exploiting web videos and images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 923–932 (2016)
Grady, L.: Random walks for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 11, 1768–1783 (2006)
Ji, J., Cao, K., Niebles, J.C.: Learning temporal action proposals with fewer labels. arXiv preprint arXiv:1910.01286 (2019)
Lin, T., Liu, X., Li, X., Ding, E., Wen, S.: Bmn: boundary-matching network for temporal action proposal generation. arXiv preprint arXiv:1907.09702 (2019)
Lin, T., Zhao, X., Shou, Z.: Single shot temporal action detection. In: Proceedings of the 25th ACM International Conference on Multimedia, pp. 988–996. ACM (2017)
Lin, T., Zhao, X., Shou, Z.: Temporal convolution based action proposal: submission to activitynet 2017. arXiv preprint arXiv:1707.06750 (2017)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: Bsn: boundary sensitive network for temporal action proposal generation. In: Proceedings of the European Conference on Computer Vision, pp. 3–19 (2018)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Long, F., Yao, T., Qiu, Z., Tian, X., Luo, J., Mei, T.: Gaussian temporal awareness networks for action localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 344–353 (2019)
Nguyen, P., Liu, T., Prasad, G., Han, B.: Weakly supervised action localization by sparse temporal pooling network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6752–6761 (2018)
Oneata, D., Verbeek, J., Schmid, C.: The lear submission at thumos 2014 (2014)
Paul, S., Roy, S., Roy-Chowdhury, A.K.: W-talc: weakly-supervised temporal activity localization and classification. In: Proceedings of the European Conference on Computer Vision, pp. 563–579 (2018)
Shou, Z., Chan, J., Zareian, A., Miyazawa, K., Chang, S.F.: Cdc: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5734–5743 (2017)
Shou, Z., Wang, D., Chang, S.F.: Temporal action localization in untrimmed videos via multi-stage cnns. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1049–1058 (2016)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Proceedings of Advances in Neural InforKFCmation Processing Systems, pp. 568–576 (2014)
Tang, K., Yao, B., Fei-Fei, L., Koller, D.: Combining the right features for complex event recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2696–2703 (2013)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4489–4497 (2015)
Wang, L., et al.: Temporal segment networks: towards good practices for deep action recognition. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 20–36. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_2
Xiao, F., Jae Lee, Y.: Video object detection with an aligned spatial-temporal memory. In: Proceedings of the European Conference on Computer Vision, pp. 485–501 (2018)
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of Thirty-Second AAAI Conference on Artificial Intelligence (2018)
Yuan, Z., Stroud, J.C., Lu, T., Deng, J.: Temporal action localization by structured maximal sums. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3684–3692 (2017)
Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Tang, X., Lin, D.: Temporal action detection with structured segment networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2914–2923 (2017)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2921–2929 (2016)
Zhou, X., Wang, D., Krähenbühl, P.: Objects as points. In: arXiv preprint arXiv:1904.07850 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Ding, X., Wang, N., Li, J., Gao, X. (2021). CRNet: Centroid Radiation Network for Temporal Action Localization. In: Ma, H., et al. Pattern Recognition and Computer Vision. PRCV 2021. Lecture Notes in Computer Science(), vol 13019. Springer, Cham. https://doi.org/10.1007/978-3-030-88004-0_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-88004-0_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-88003-3
Online ISBN: 978-3-030-88004-0
eBook Packages: Computer ScienceComputer Science (R0)