
Abstract
Time series modelling and forecasting techniques have a wide spectrum of applications in several fields including economics, finance, engineering and computer science. Most available modelling and forecasting techniques are applicable to a specific underlying phenomenon and its properties and lack generality of application, while more general forecasting techniques require substantial computational time for training and application. Herewith, we present a general modelling framework based on a recursive Schur - complement technique, that utilizes a set of basis functions, either linear or non-linear, to form a model for a general time series. The basis functions need not be orthogonal and their number is determined adaptively based on fitting accuracy. Moreover, no assumptions are required for the input data. The coefficients for the basis functions are computed using a recursive pseudoinverse matrix, thus they can be recomputed for different input data. The case of sinusoidal basis functions is presented. Discussions around stability of the resulting model and choice of basis functions is also provided. Numerical results depicting the applicability and effectiveness of the proposed technique are given.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

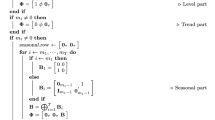

Keywords
1 Introduction
General time series modelling and forecasting has become an essential tool in several scientific fields and business sectors, spanning from physics and engineering to workforce prediction and finance. Several methods have been proposed in the literature for modelling and forecasting time series based on either statistical or Machine Learning techniques. The most notable methods in the statistical methods class include Exponential Smoothing (ES), Auto-Regressive Integrated Moving Average (ARIMA), State Space and Structural models, Kalman filter, Nonlinear models and Generalized Auto-Regressive Conditionally Heteroscedastic (GARCH) models.
Exponential Smoothing (ES) was proposed in the1960 s by Brown, Holt and Winters [3, 11, 27], has been used extensively along with its variants due to its simplicity and adaptability to various scientific fields [14, 25]. Auto-Regressive (AR), Auto-Regressive Moving Average (ARMA) and Auto-Regressive Integrated Moving Average (ARIMA) models were first proposed by Box and Jenkins [2] in the1970 s. Estimation techniques for the parameters of such methods have been discussed in [2]. Several univariate time series forecasting variants of such models have been proposed in the literature including ARARMA [18], Vector ARIMA (VARIMA) [21, 23], Automatic univariate ARIMA type models [24] and seasonal approaches such as STL or \(X-11\) [4, 5]. In the1980 s, state space models have been also used including Dynamic Linear Models (DLM) [9] and Basic Structural Models (BSM) [10] along with several variants [20]. In the quantitative finance domain Generalized Auto-Regressive Conditionally Heteroscedastic (GARCH) models [6] have been used. Nonlinear variants that handle asymmetric volatility have been also presented and studied [1, 17].
Research around non-linear modelling techniques has also been conducted however not in such extent. This is primarily because of their increased complexity and the lack of closed form formulas. In this field notable contributions include the work of Wiener [26] and others [19]. Detailed overview on the advances of time series modelling and forecasting techniques over the last decades are given in [8] and references inside. Moreover, large scale benchmarking of popular modelling and forecasting techniques are given in [15].
Despite the popularity and wide use of the aforementioned techniques, they are mostly dedicated tools tuned specifically to a use case relying on restrictive assumptions for the form and nature of the data. General models such as Artificial Neural Networks or Support Vector Machines handle those limitations but they require substantial amounts of data, increased training and retraining times, as well as substantial tuning of the large number of hyperparameters. A different approach is followed by Fast Orthogonal Search (FOS) and its variants [12, 13, 16], which can form general models using combinations of linear and non-linear basis functions. These methods are based on Gram - Schmidt and Modified Gram - Schmidt orthogonalization as well as a Cholesky type factorization approaches. These methods build the model incrementally based on a re-orthogonalization approach. The time series is projected to this orthogonal set and until a prescribed modelling error is achieved. However, inherently parallel orthogonalization procedures have instabilities and stable variants are inherently sequential, thus cannot take advantage of novel multicore architectures. Furthermore, for models composed of a large number of trigonometric components, retraining the model requires re-computation of the coefficients performed by backward - forwards substitution, which is inherently sequential.
In this article a novel inherently parallel Schur complement based pseudoinverse matrix modelling and forecasting technique is proposed. The proposed scheme is based on a recursive pseudoinverse matrix to form a model based on a predefined set of linearly independent (linear or non-linear) basis functions. Basis functions are accumulated recursively into the model until a prescribed error is achieved. The stability of the model is ensured by enforcing positive definiteness of the dot product matrix of basis functions through monitoring of error reduction as well as monitoring the magnitude of the diagonal elements. Retraining of the produced model is limited to the pseudoinverse matrix by vector product. By exploiting orthogonality features, computing the residual time series is avoided, improving computational complexity. Discussions and implementation details regarding the computation of the pseudoinverse matrix and model formation are also provided. The case of sinusoidal basis functions is also discussed along with a technique to accurately determine frequencies based on the proposed approach. The efficiency and applicability of the proposed scheme is assessed in a variety of time series with different characteristics.
In Sect. 2, the recursive Schur complement based pseudoinverse matrix of basis functions is introduced. In Sect. 3, the Schur complement based pseudoinverse matrix is utilized in the design of the proposed modelling technique in order to computed the weights of the respective basis. Discussions on the stability of the scheme and implementation details are also provided. In Sect. 4, the case of sinusoidal basis functions is examined and discussed. In Sect. 5, numerical results are presented depicting the applicability and accuracy of the proposed scheme along with discussions for several time series.
2 Recursive Schur Complement Based Pseudoinverse Matrix of Basis Functions
Let us consider a matrix composed of a set of n basis functions:
where \(x_i(t),1\le i \le n\) are the basis functions and t is the time variable. We can expand a general time series y based on the \(x_i(t)\):
where \(\epsilon (t)\) is the error term and \(a_i,1\le i \le n\) are the unknown coefficients that have to be determined. The Eqs. (2) can be written in block form:
or equivalently,
Thus, the coefficients can be determined by solving the least squares linear system (3) or through the pseudoinverse \(X^{+}\) (4). However, in many cases the basis functions are not known a priori and are computed iteratively or recurrently up to prescribed tolerance. This requires formation and solution of multiple least squares linear systems, which increases substantially the computational work. To avoid such issues modelling techniques such as Fast Orthogonal Search (FOS) and variants [12, 13, 16] have been proposed, based on Gram - Schmidt and Modified Gram - Schmidt orthogonalization as well as Cholesky factorization type approaches. These methods build the model incrementally by adding basis functions and re-orthogonalize with the already computed ones in order to project the time series and reduce the modelling error.
In order to avoid computational costs and instabilities involved in using orthogonalization procedures, while retaining the flexibility of incrementally building the model, a novel approximate inverse scheme is proposed. Let as consider the matrix \(X_i\) containing up to the i-th base and an additional base F:
or:
where \(b=X_i^T F\) and \(d=F^T F\). It should be noted that the matrix \(X^T_{i+1} X_{i+1}\) is Symmetric Positive Definite and thus invertible, under the assumption that the basis function are linearly independent.
Computing the inverse of the matrix \(K_{i+1}\) enables formation of the pseudoinverse \(X_{i+1}^{+}\) and consequently the computation of the coefficients \(a_i\) to form the model. The matrix \(K_{i+1}\) can be factored to enable easier inversion and avoid the update step for the elements of the inverse of the matrix \(K_{i}\), which is essential in case of non-factored inverse matrices [7]:
or equivalently:
where the matrix \(D_i\) retains the Schur complements \(s_i\) corresponding to each addition of a basis functions. The Schur complements are of the form: \(s_i = d - b^T G_{i} D^{-1}_{i} G^T_{i} b \). Due to the symmetric nature of the inverse \(K^{-1}_{i+1}\) only the factors \(D_{i+1}\) and \(G_{i+1}\) are required. Thus, we have:
where \(z=G_i^T b\). Addition of a new basis is limited to simple “matrix times vector” operations, which can be efficiently performed in modern CPUs or accelerators such as GPUs. The storage requirements for the inverse are limited to the upper triangular matrix \(G_i\), which retains \(i(i+1)/2\) elements, and the diagonal matrix \(D_i\) retaining i elements.
In order to avoid breakdowns in case of weak linear independence between different basis functions or loss of numerical precision, a condition on the magnitude of the diagonal element (Schur Complement) should be imposed. If the diagonal element is close to machine precision, in practice less than \(\sqrt{\epsilon _{mach}}\), it is substituted with \(\sqrt{\epsilon _{mach}}\), thus avoiding breakdowns.
3 Schur Based Pseudoinverse Matrix Modelling and Forecasting
The choice of basis functions for creating a model can be arbitrary, since they are evaluated and stored in the columns of matrix X. However, the amount and type of functions chosen affects the accuracy of the model and computational work. Considering the basis functions of Eq. (1), the general time - series of Eq. (2) and the recursive inverse matrix of Eq. (8) we can obtain the coefficients \(a_{i}\), after the addition of the \(i+1\) basis function, as follows:
where \(s_i = F^T F - F^T X_i G_{i}D_i^{-1}G^T_{i} X_i^T F \). The addition of a basis function involves updating of the values of already computed coefficients \(a_i\) corresponding to the i basis functions. Let \(g_{i+1} = -G_{i}D_i^{-1}G^T_{i} X_i^T F\) then we have:
where \(a_i=G_i D^{-1}_i G^T_i X_i^T y\) and \(s_i=F^T(F+X_i g_{i+1})\). The coefficients \(a^*_i\) are updated after the inclusion of basis function F, while matrix \(X_i\) retains all basis functions up to i-th. The residual time series update equation, with respect to the addition of a new basis function can be formed using Eq. (11) as follows:
or:
Using Eq. (13) the norm of the residual, after addition of a basis function, can be computed as follows:
where \(P_{X_i}\) is an orthogonal projection operator onto the subspace spanned by the columns of \(X_i\). The Eq. (14) implies also the following:
Thus, we have:
or
Equation (17) can be used to assess progress of fitting, instead of computing the norm of the residual at each iteration, substantially improving performance especially in the case of increased number of basis functions. Moreover, the quantity \(b^2 s\) is positive since matrix \(X_i^T X_i\) is Symmetric Positive Definite, thus its Schur Complement is also Symmetric Positive Definite, leading to monotonic reduction of the norm of the residual \(r_{i+1}\).

The initial conditions for Eqs. (11) and (13) are the following:
and
The procedure for computing the coefficients \(a_i\) is described in the Algorithm 1. The chosen basis functions are evaluated for \(t=1,...,T\) and stored in the columns of matrix \(X\). Thus, the model can be formed by computing \(Xa\). The formed model can be used to compute forecasts up to predefined horizon \(h\). This can be achieved by initially progressing the set of basis function in time, e.g. evaluate them for \(t^*=T+1,...,T+h\) and store them to the columns of a matrix \(X^*=[x_1(t^*) \ldots x_n(t^*)]\). Then, the forecasts can be computed by \(X^*a\). In practice, the choice of basis functions can be arbitrary, e.g. linear or non-linear or combinations.
The stability of the model with respect to each addition of a basis function can be ensured by allowing basis function to be added only if the error reduction, caused by such an addition, is positive (\(b^2 s \ge 0\)) and the reduction of the error does not render the error term negative \(\rho <0\) (\(\rho \ge b^2 s\)). These conditions ensure invertibility of the matrix \(X_i^T X_i\) and positive definiteness of the inverse matrix \(G_i D_i ^{-1} G_i^T\), by allowing inclusion of basis functions that are suitably linearly independent to the already selected ones.
4 The Case of Sinusoidal Basis Functions
Sinusoidal basis functions can be used to form a model for general time series. In the case of strong trigonometrical phenomena in a time series, such basis functions can be used to capture them. The sinusoidal basis functions are of the following form:
where \(\omega _i\) is the frequency. Estimation of frequencies can be performed using techniques such as the Fast Fourier Transform through the spectrum or the Quinn - Fernandes algorithm [22]. The proposed scheme allows for determining frequencies with arbitrary accuracy through frequency searching similar to the procedure described in [12]. In case of the proposed technique basis function of the form \(F=cos(\omega _i t)\) followed by a basis function of the form \(F=sin(\omega _i t)\) for various frequencies \(\omega _i \in (0,pi]\) are fitted and the frequency that results in maximum error reduction is selected. The selected frequency becomes part of the model, is excluded from the search space, and the procedure continues until the error criterion is met. The search space \((0,pi)\) is sampled based on a prescribed sampling interval \(\delta \omega \). The choice of \(\delta \omega \) affects the accuracy in which the frequencies are determined. The advantages of this technique are that frequencies can be determined in parallel while the residual time series need not be computed explicitly.
In order to assess the accuracy of the technique the following example is provided. Let us consider the following:
where \(\sigma (t)\) is following uniform random distribution with average equal to \(0.5\). The frequencies \(\omega _i\) are: \(\omega _1 = 0.0546\), \(\omega _2 = 0.83120\), \(\omega _3 =1.87120 \) and \(\omega _4 = 1.91320\). The frequencies are estimated using Fast Fourier Transform (FFT), Quinn - Fernandes method based on FFT as initial guess coupled with Ordinary Least Squares (OLS) method and the proposed technique. The results are given in Table 1.
The choice of \(\delta \omega \), in the proposed scheme, should be less than the sampling interval of the Fast Fourier Transform, e.g. \(\delta \omega \le \frac{2*pi}{N}{} \), in order to allow accurate determination of the frequencies and avoid undersampling.
The proposed technique can be used to estimate the frequency to improved accuracy compared to FFT or the QF-OLS method. The proposed scheme can be coupled also with either the FFT or QF-OLS method and hybrid schemes can be designed leveraging the advantages of those schemes. This will be studied in future work.
5 Numerical Results
In this section the applicability and accuracy of the proposed scheme is examined by applying the proposed technique to three time series. The two error measures used to assess the forecasting error was Mean Absolute Percentage Error (MAPE) and Mean Absolute Deviation (MAD):
where \(y_i\) are the actual values, \(\hat{y}_i\) the forecasted values and \(T\) the length of the test set. The basis functions chosen to model the selected time series were:
The linear and exponential basis were added to automatically capture such trends in the data. It should be mentioned that the time variable \(t\) is scaled for the linear and exponential components to improve numerical behavior during inversion of the matrix of basis functions.
5.1 US Airline Passenger Volume
This US airline passenger volume dataset was extracted from R Studio and is composed of monthly total volumes of passengers spanning from January 1949 to December 1960 (144 samples). The training part was composed of \(75\%\) of the dataset, while the test part was composed of \(25\%\) of the dataset, specifically the training part included \(108\) samples and the test part included \(36\) samples, as presented in Fig. 1. The prescribed interval \(\delta \omega \) for frequency search was set to \(0.001\) and the prescribed tolerance for fitting the model was set to \(\epsilon =0.01\). The forecasted values along with the actuals are given in Fig. 2. The MAPE and MAD of the forecasts were \(9.3474\) and \(40.0410\), respectively. From Fig. 2 we observe that the proposed scheme captured the exponential and linear tendency automatically as well as the underlying trigonometric phenomena, without requiring any pre-processing steps for the input data apart from maximum scaling.

Train and test parts for the US airline passenger volume dataset.

Forecasted and actual values for the US airline passenger volume dataset.
With respect to the value of the coefficients comprising the model the time series exhibits a significant exponential component, a weak linear component along with a strong low frequency harmonic component, because of the yearly periodicity of the time series.
5.2 Monthly Expenditure on Eating Out in Australia
The monthly expenditure on eating out in Australia dataset was extracted from R Studio and is composed of the monthly expenditure on cafes, restaurants and takeaway food services in Australia in billion dollars. The dataset is composed of 426 samples spanning a period from April 1982 to September 2017. The training part was composed of \(\approx 80\%{ ofthedatasetwhilethetestpartwascomposedof}\approx 20\%{ ofthedataset},\,{ specificallythetrainingpartincluded}342{ samplesandthetestpartincluded}84\) samples, as presented in Fig. 3. The prescribed interval \(\delta \omega { forfrequencysearchwassetto}0.001{ andtheprescribedtoleranceforfittingthemodelwassetto}\epsilon =0.01\). The forecasted values along with the actuals are given in Fig. 4. The MAPE and MAD of the forecasts were 4.5292 and 0.1465, respectively.

Train and test parts for the monthly expenditure on eating out in Australia dataset.

Forecasted and actual values for the US airline passenger volume dataset.
With respect to the value of the coefficients comprising the model the time series exhibits a strong exponential component, a strong linear component along with a relatively significant medium frequency harmonic components.
5.3 Call Volume for a Large North American Bank
The call volume for a large North American bank dataset was extracted from R Studio and is composed of the volume of calls, per five minute intervals, spanning 164 d starting from 3 March 2003. The dataset is composed of 27716 samples. The training part was composed of \(\approx 80\%{ ofthedatasetwhilethetestpartwascomposedof}\approx 20\%\) of the dataset, specifically the training part included 22325 samples and the test part included 5391 samples, as presented in Fig. 5. The prescribed interval \(\delta \omega { forfrequencysearchwassetto}10^{-5}{} { andtheprescribedtoleranceforfittingthemodelwassetto}\epsilon =0.088.{ Thevalueofthetolerance}\epsilon \) is chosen as below that margin the rate of error reduction slows down significantly due to the presence of noise in the form of a large number of frequencies with the same magnitude in the spectrum. This issue can be overcome by increasing the samples of the spectrum, however this substantially increases the computational work, without significant improvement in the forecasting error. The forecasted values along with the actuals are given in Fig. 6. The MAPE and MAD of for the forecasts were 15.1580 and 25.4576, respectively.

Train and test parts for the call volume for a large North American bank dataset.

Forecasted and actual values for call volume for a large North American bank dataset.
With respect to the value of the coefficients the model has a weak exponential component that is counteracted by a weak linear component. There are also strong low frequency components that contribute significantly in the reduction of the error.
5.4 Discussions
The proposed scheme was able to capture the dominant characteristics of the different time series. The choice of the basis functions substantially affects the estimation and the forecasting error. For example, for the model problem of Subsection 5.3 the linear and exponential basis do not contribute significantly to the accuracy of the model, while also increasing the computational complexity since the dimensions of the pseudoinverse matrix grow. However, to preserve generality and wide applicability, a common set of basis functions was retained for all experiments.
Another important issue is the estimation of frequencies, which for the low value of the \(\delta \omega \) parameter requires substantial computational work especially in the case of large training data. In order to reduce computational complexity, frequency estimation can be performed by means of either FFT or the Quinn - Fernandes algorithm [22] or hybrid approaches which will be studied in future research.
The generality of the approach allows the incorporation of basis functions based on nonlinear modelling techniques such as Artificial Neural Networks (ANN) and Support Vector Machines (SVM) trained by subsets of the available dataset. The effect of such basis functions will be studied also in future research.
6 Conclusion
A novel Schur complement based pseudoinverse matrix approach for modelling and forecasting general time series has been proposed. The proposed technique can incorporate linear and non-linear components during model formation, thus avoiding preprocessing and transformation of the time series or restrictive assumptions related to the statistical properties of the data. Stability of the model is ensured by enforcing positive definiteness of the dot product matrix of basis functions \((X^T X)\) and its inverse, and monotonic reduction of the error. A frequency detection technique is also presented based on the proposed scheme. The proposed scheme does not require preprosessing of time series and is assessed by modelling several time series exhibiting combinations of exponential, linear, trigonometric and random characteristics. Moreover, the model relies on a single parameter and it is suitable for modelling general time series.
Future work is directed towards the design of a parallel approximate pseudoinverse matrix approach in order to reduce storage requirements especially in the case of large number of basis functions. Moreover, an adaptive approach for frequency estimation is under further research.
Change history
09 June 2021
Chapter 18, “Modelling and Forecasting Based on Recurrent Pseudoinverse Matrices” was previously published non-open access. This have now been changed to open access under a CC BY 4.0 license and the copyright holders updated to ‘The Author(s)’ and the acknowledgement section added. The book has also been updated with this change.
In chapter 44, in reference 34, the surname of the first author was incorrect. The surname has been corrected from “Porti” to “Potortì.”
References
Awartani, B.M., Corradi, V.: Predicting the volatility of the S&P-500 stock index via GARCH models: the role of asymmetries. Int. J. Forecast. 21(1), 167–183 (2005)
Box, G.E.P., Jenkins, G.M.: Time Series Analysis Forecasting and Control. Holden Day, San Francisco (1976)
Brown, R.G.: Smoothing. Forecasting and prediction of discrete time series. Englewood Cliffs, NJ, Prentice Hall (1963)
Cleveland, R.B., Cleveland, W.S., McRae, J.E., Terpenning, I.: STL: a seasonal-trend decomposition procedure based on loess (with discussion). J. Official Stat. 6, 3–73 (1990)
Dagum, E.B.: Revisions of time varying seasonal filters. J. Forecast. 1(2), 173–187 (1982). https://doi.org/10.1002/for.3980010204
Engle, R.F.: Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica 50(4), 987–1007 (1982)
Filelis-Papadopoulos, C.K.: Incomplete inverse matrices. Numer. Linear Algebra Appl. (2021). https://doi.org/10.1002/nla.2380
Gooijer, J.G., Hyndman, R.: 25 years of IIF time series forecasting: a selective review. In: Monash Econometrics and Business Statistics Working Papers 12/05, Monash University, Department of Econometrics and Business Statistics (2005). https://econpapers.repec.org/paper/mshebswps/2005-12.htm
Harrison, P.J., Stevens, C.F.: Bayesian forecasting. J. R. Stat. Soc. Series B (Methodol.) 38(3), 205–247 (1976)
Harvey, A.C.: Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge University Press, Cambridge (1989)
Holt, C.C.: Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 20, 5–13 (2004)
Korenberg, M.J., Paarmann, L.D.: Orthogonal approaches to time-series analysis and system identification. IEEE Signal Process. Mag. 8(3), 29–43 (1991)
Li, X., Tian, J., Wang, X., Dai, J., Ai, L.: Fast orthogonal search method for modeling nonlinear hemodynamic response in fMRI. In: Amini, A.A., Manduca, A. (eds.) Medical Imaging 2004: Physiology, Function, and Structure from Medical Images. International Society for Optics and Photonics, SPIE, vol. 5369, pp. 219–226 (2004). https://doi.org/10.1117/12.536165
Makridakis, S., Hibon, M.: Exponential smoothing: the effect of initial values and loss function on post-sample forecasting accuracy. Int. J. Forecast 7, 317–330 (1991)
Makridakis, S., Spiliotis, E., Assimakopoulos, V.: The m4 competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 36(1), 54–74 (2020). https://doi.org/10.1016/j.ijforecast.2019.04.014, m4 Competition
Osman, A., et al.: Adaptive fast orthogonal search (fos) algorithm for forecasting streamflow. J. Hydrol. 586, 124896 (2020).https://doi.org/10.1016/j.jhydrol.2020.124896, http://www.sciencedirect.com/science/article/pii/S0022169420303565
Pagan, A.: The econometrics of financial markets. J. Empirical Finance 3(1), 15–102 (1996)
Parzen, E.: Ararma models for time series analysis and forecasting. J. Forecast. 1(1), 67–82 (1982). https://doi.org/10.1002/for.3980010108
Poskitt, D., Tremayne, A.: The selection and use of linear and bilinear time series models. Int. J. Forecast. 2(1), 101–114 (1986). https://doi.org/10.1016/0169-2070(86)90033-6
Proietti, T.: Comparing seasonal components for structural time series models. Int. J. Forecast. 16(2), 247–260 (2000). https://doi.org/10.1016/S0169-2070(00)00037-6
Quenouille, M.H.: The Analysis of Multiple Time-Series. London, Griffin. 2nd edn. (1968)
Quinn, B.G., Fernandes, J.M.: A fast efficient technique for the estimation of frequency. Biometrika 78(3), 489–497 (1991)
Riise, T., Tjozstheim, D.: Theory and practice of multivariate arma forecasting. J. Forecast. 3(3), 309–317 (1984). https://doi.org/10.1002/for.3980030308
Tashman, L.J.: Out-of-sample tests of forecasting accuracy: an analysis and review. Int. J. Forecast. 16(4), 437–450 (2000)
Taylor, J.W.: Exponential smoothing with a damped multiplicative trend. Int. J. Forecast. 19, 273–289 (2003)
Wiener, N.: Non-linear Problems in Random Theory. Wiley, London (1958)
Winters, P.R.: Forecasting sales by exponentially weighted moving averages. Manage. Sci. 6, 324–342 (1960)
Acknowledgement
This publication has emanated from research conducted with the financial support of Science Foundation Ireland under Grant number [18/SPP/3459]. For the purpose of Open Access, the author has applied a CC BY public copyright licence to any Author Accepted Manuscript version arising from this submission.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this paper

Cite this paper
Filelis-Papadopoulos, C.K., Kyziropoulos, P.E., Morrison, J.P., O‘Reilly, P. (2021). Modelling and Forecasting Based on Recurrent Pseudoinverse Matrices. In: Paszynski, M., Kranzlmüller, D., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M. (eds) Computational Science – ICCS 2021. ICCS 2021. Lecture Notes in Computer Science(), vol 12745. Springer, Cham. https://doi.org/10.1007/978-3-030-77970-2_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-77970-2_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-77969-6
Online ISBN: 978-3-030-77970-2
eBook Packages: Computer ScienceComputer Science (R0)