
Abstract
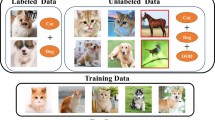
Labeled samples are crucial in semi-supervised classification, but which samples should we choose to be the labeled samples? In other words, which samples, if labeled, would provide the most information? We propose a method to solve this problem. First, we give each unlabeled examples an initial class label using unsupervised learning. Then, by maximizing the mutual information, we choose the samples with most information to be user-specified labeled samples. After that, we run semi-supervised algorithm with the user-specified labeled samples to get the final classification. Experimental results on synthetic data show that our algorithm can get a satisfying classification results with active query selection.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Blum, A., Mitchell, T.: Combining labeled and unlabeled data with co-training. In: Proceedings of the 11th Annual Conference on Computational Learning Theory, Madison, WI, pp. 92–100 (1998)
Blum, A., Chawla, S.: Learning from Labeled and Unlabeled Data using Graph Mincuts. In: ICML (2001)
Belkin, M., Niyogi, P.: Laplacian Eigenmaps for Dimensionality Reduction and Data Representation. Neural Computation (June 2003)
Belkin, M., Niyogi, P., Sindhwani, V.: On Manifold Regularization. Department of Computer Science, University of Chicago, TR-2004-05
Krishnapuram, B., Williams, D., Xue, Y., Hartemink, A., Carin, L., Figueiredo, M.A.T.: On Semi-Supervised Classification. In: NIPS (2004)
Zhou, D., Bousquet, O., Lal, T.N., Weston, J., Schoelkopf, B.: Learning with Local and Global Consistency. In: NIPS (2003)
Freund, Y., Seung, H.S., Shamir, E., Tishby, N.: Selective sampling using the query by committee algorithm. Machine Learning 28, 133–168 (1997)
Nigam, K.: Using Unlabeled Data to Improve Text Classification. PhD thesis, Carnegie Mellon University Computer Science Dept. (2001)
Szummer, M., Jaakkola, T.: Partially labeled classification with markov random walks. In: NIPS (2001)
Tong, S., Koller, D.: Support vector machine active learning with applications to text classification. In: ICML (2000)
Zhu, X., Lafferty, J., Ghahramani, Z.: Combining active learning and semi-supervised learning using Gaussian fields and harmonic functions. In: ICML (2003)
Zhu, X., Ghahramani, Z., Lafferty, J.: Semi-supervised learning using Gaussian fields and harmonic functions. In: ICML (2003)
Zhu, X.: Semi-Supervised Learning with Graphs. PhD thesis, Carnegie Mellon University Computer Science Dept. (2005)
Zhou, Z.-H., Li, M.: Semi-supervised regression with co-training. In: International Joint Conference on Artificial Intelligence (2005)
Zhou, Z.-H., Li, M.: Tri-training: exploiting unlabeled data using three classifiers. IEEE Trans. Knowledge and Data Engineering 17, 1529–1541 (2005)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2006 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Wang, J., Luo, S. (2006). Semi-supervised Classification with Active Query Selection. In: Yeung, DY., Kwok, J.T., Fred, A., Roli, F., de Ridder, D. (eds) Structural, Syntactic, and Statistical Pattern Recognition. SSPR /SPR 2006. Lecture Notes in Computer Science, vol 4109. Springer, Berlin, Heidelberg. https://doi.org/10.1007/11815921_81
Download citation
DOI: https://doi.org/10.1007/11815921_81
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-37236-3
Online ISBN: 978-3-540-37241-7
eBook Packages: Computer ScienceComputer Science (R0)
